作者:MeshCloud脉时云公有云架构师吴子成
引言
在当今信息时代,数据处理和分析正变得越来越重要。Google BigQuery作为一种强大的云端数据仓库解决方案,以其高速、弹性和易用性备受欢迎。与此同时,数据科学家和分析师们通常倾向于使用Python中的DataFrame来处理和操纵数据。本文将介绍如何从DataFrame加载数据至BigQuery,并在此过程中忽略多余字段,从而轻松高效地进行数据处理。
Google BigQuery
Google BigQuery是一种完全托管的大数据分析平台,适用于在云端处理海量结构化数据。以下是关于BigQuery的一些关键特点:
- 云端托管: BigQuery完全托管于Google Cloud平台,无需用户操心硬件或基础架构问题。用户可以专注于数据分析和查询。
- 弹性计算: BigQuery采用分布式计算,能够自动调整资源以适应查询的规模。这意味着无论是小型查询还是复杂的大规模分析,BigQuery都能以高速度处理数据。
- SQL查询: BigQuery支持标准SQL查询语言,使得用户可以使用熟悉的SQL语法来查询和分析数据。同时,它还支持用户定义的函数、窗口函数等高级SQL特性。
- 分层存储: BigQuery支持分层存储,即将热数据存储在高性能的存储层,将冷数据存储在低成本的存储层,从而平衡了性能和成本。
- 实时分析: BigQuery可以与其他实时数据流处理系统(如Pub/Sub)集成,使用户能够进行实时数据分析和查询。
DataFrame
DataFrame是一种在Python中非常流行的数据结构,常用于数据分析和操作。它是Pandas库的核心对象,具有以下特点:
- 二维表结构: DataFrame是一个类似于二维表格的数据结构,每一列可以是不同的数据类型。这使得DataFrame适用于各种不同类型的数据。
- 数据操作: DataFrame提供了丰富的数据操作和处理功能,包括数据过滤、排序、分组、聚合等。用户可以使用类似SQL的语法进行数据操作。
- 灵活性: DataFrame允许用户对数据进行灵活的转换和处理,包括数据清洗、填充缺失值、数据格式转换等。
- 数据可视化: DataFrame可以与各种数据可视化库(如Matplotlib和Seaborn)集成,便于生成直观的图表和图形。
- 数据源: DataFrame可以从多种数据源加载数据,如CSV文件、数据库查询结果、Excel文件等。
- 性能优化: 尽管DataFrame提供了强大的功能,但在处理大规模数据时可能会遇到性能问题。用户需要注意使用适当的技巧和优化方法。
Google BigQuery和DataFrame分别代表了云端大数据分析和本地数据处理两个方面的核心工具。通过结合它们的优势,用户可以在云端高效地处理大规模数据,并在本地使用Python进行数据清洗、分析和可视化,从而获得全面而深入的数据洞察力。
准备工作
1) 创建BigQuery的Dataset和Table
在Google BigQuery中,Dataset和Table是组织和存储数据的基本单元。Dataset是一个逻辑容器,用于组织和存储相关的数据表,而Table则是实际存储数据的地方。以下是关于如何创建Dataset和Table的详细介绍:
创建Dataset:
- 导航到BigQuery:在Google Cloud Console中,左侧导航栏中找到 “BigQuery” 并点击进入。
- 创建新的Dataset:在BigQuery控制台中,点击左侧面板的 “数据集”,然后点击页面顶部的 “创建数据集”。
- 填写Dataset信息:
- 数据集ID: 为数据集指定一个唯一的ID。
- 数据集名称: 为数据集起一个易于识别的名称。
- 数据集位置: 选择数据集所在的地理位置。
- 完成创建:点击 “创建数据集” 按钮,即可创建新的Dataset。
创建Table:
- 在BigQuery控制台中,找到您刚刚创建的Dataset,并点击进入。
- 创建新的Table:点击页面顶部的 “创建表格”。
- 选择数据源:
- 创建模式: 选择 “自定义”,以手动定义表的结构。
- 定义表结构:
- 表名称: 为表指定一个唯一的名称。
- 模式: 定义表的列名、数据类型和其他属性。
- 分区和分区字段(可选): 您可以选择将表分成分区以提高查询性能。
- 视图定义(可选): 如果要创建一个视图而不是物理表,您可以在这里定义查询。
在Table被成功创建后,您可以使用各种方式将数据加载到该表中,包括使用Python中的Pandas DataFrame,命令行工具,以及Google Cloud SDK等。务必确保您已经理解表的结构和所需字段,以及如何将数据与Table相匹配。这将确保您在数据加载和查询时取得正确的结果。
在本文示例中,提前定义好了table的字段用于测试,如下图所示:
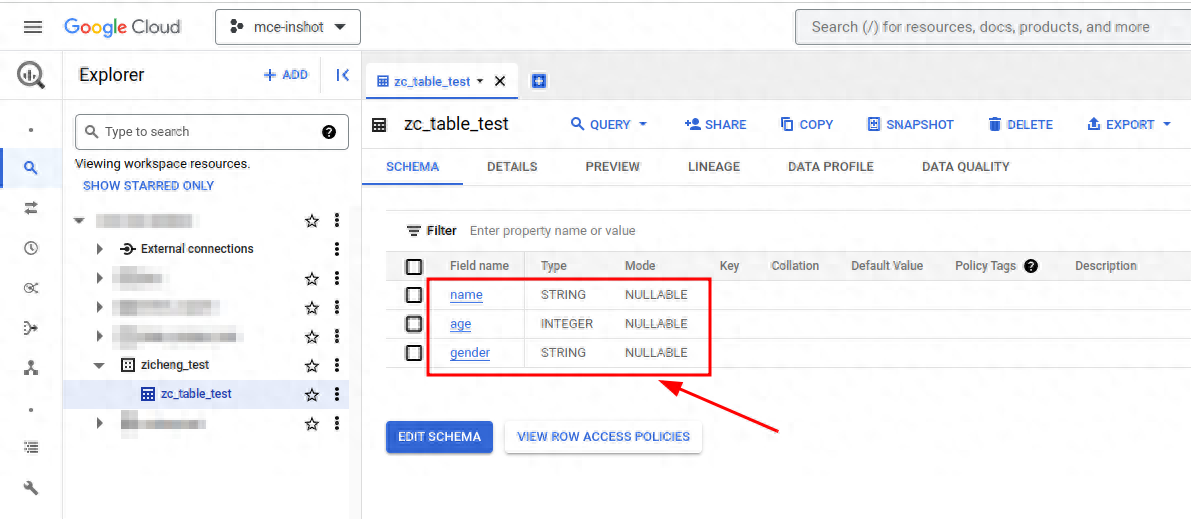
2) 创建服务帐号并配置IAM权限
- 创建Service Account: 在Google Cloud Console中创建一个新的Service Account,并选择适当的角色[1]。最常见的是将Service Account赋予 “BigQuery 数据编辑者”(BigQuery Data Editor)的角色,这将允许Service Account编辑数据表。
- 生成JSON凭据: 创建Service Account后,您将能够下载一个包含JSON凭据的密钥文件。此文件包含用于在代码中进行身份验证的信息。
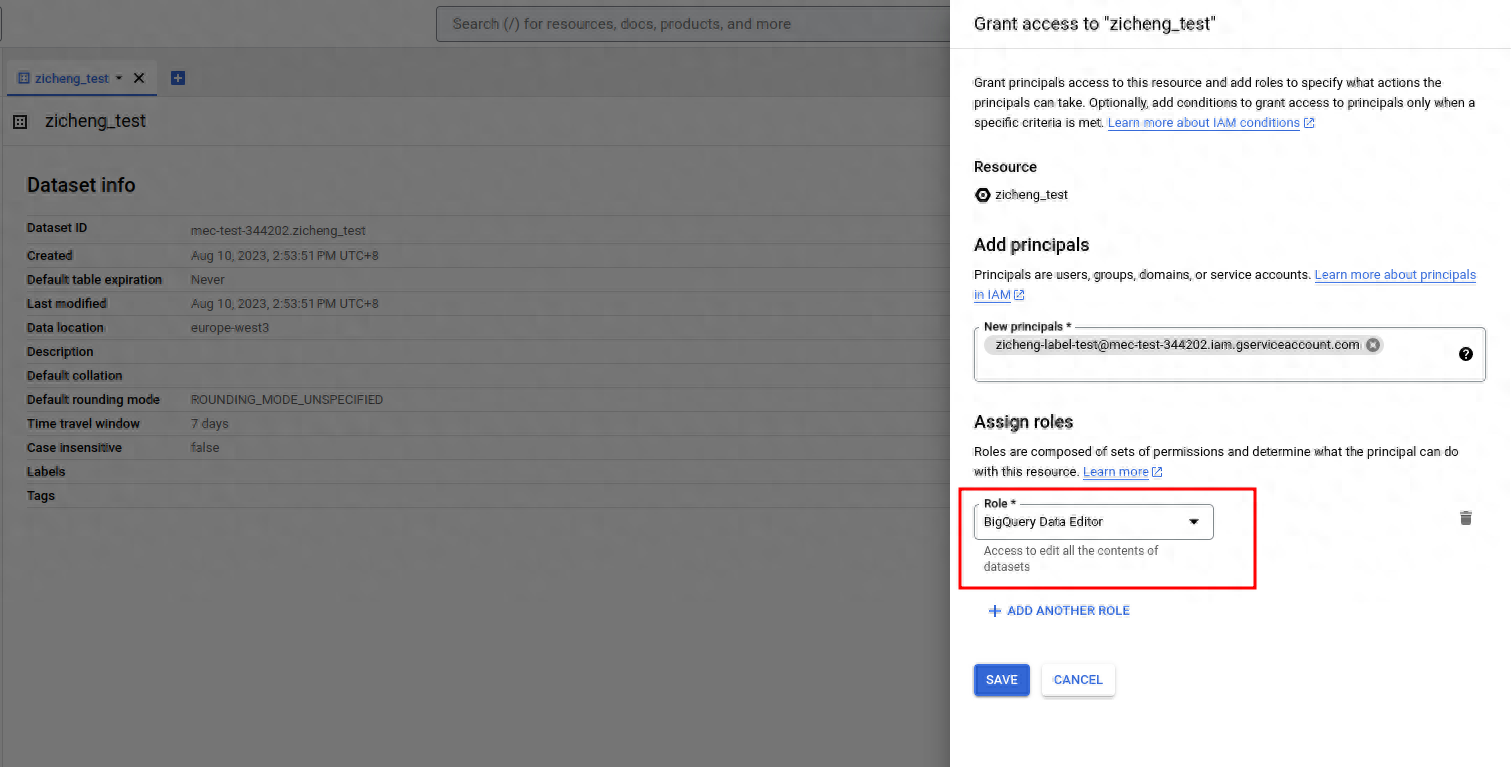
- 分配Dataset和Table权限(可选): 如果您希望只允许Service Account对具体的某一个Dataset或者Table有操作权限,那么可以参考文档[2]赋予权限,而不是在IAM赋权。选中特定的Dataset,点击Sharing > Permissions,选择Add principal,对Service Account添加BigQuery Data Editor的角色,允许访问特定的Dataset。
3) 准备好python环境
本文案例中GCE的操作系统为Centos 7,软件版本为Python 3.6.8和pip 21.3.1
实施步骤
1) 方案介绍
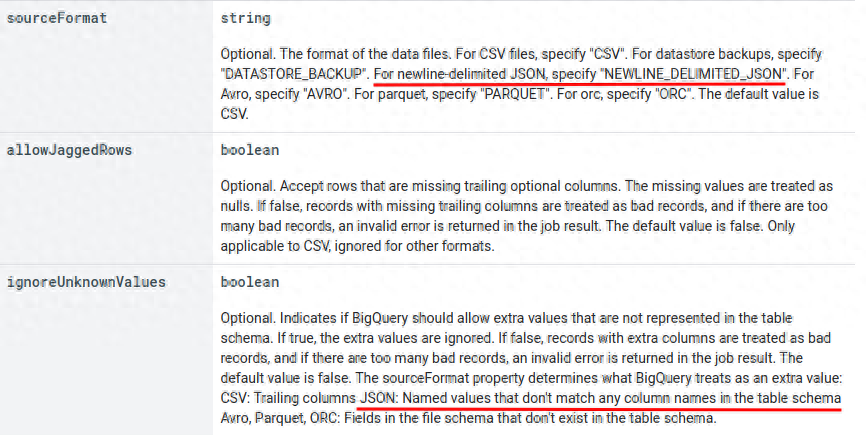
根据BigQuery官方库的介绍[3],当sourceFormat为JSON,且ignoreUnknownValues为True时,对导入的数据忽略多余的字段。那么本文中示例的方案,就是将DataFrame转化成JSON。
2) 本文案例的Demo代码
from google.cloud import bigquery
from google.oauth2 import service_account
import pandas as pd
import json
# Path to your service account key JSON file
service_account_json = '/root/zicheng.json'
# Authenticate using the service account key
credentials = service_account.Credentials.from_service_account_file(service_account_json)
# Initialize a BigQuery client
client = bigquery.Client(credentials=credentials)
# Initialize a Pandas DataFrame
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"gender": ["F", "M", "M"],
"extra": ["foo", "bar", "baz"]
}
df = pd.DataFrame(data)
# Convert DataFrame to JSON objects
json_records = df.to_json(orient='records')
records = json.loads(json_records)
# Define the BigQuery destination table
dataset_id = "zicheng_test"
table_id = "zc_table_test"
table_ref = client.dataset(dataset_id).table(table_id)
# Define the BigQuery schema
schema = [
bigquery.SchemaField("name", "STRING"),
bigquery.SchemaField("age", "INTEGER"),
bigquery.SchemaField("gender", "STRING")
]
# Create a BigQuery insert job with schema and source format
job_config = bigquery.LoadJobConfig(schema=schema, ignore_unknown_values=True, source_format=bigquery.SourceFormat.NEWLINE_DELIMITED_JSON)
job = client.load_table_from_json(records, table_ref, job_config=job_config)
# Wait for the job to complete
job.result()
if job.state == "DONE":
print("Data loaded successfully from DataFrame to BigQuery with ignored extra fields.")
else:
print("Data load job failed.")3) 验证
在测试的Demo中,多余的字段是”extra”: [“foo”, “bar”, “baz”]
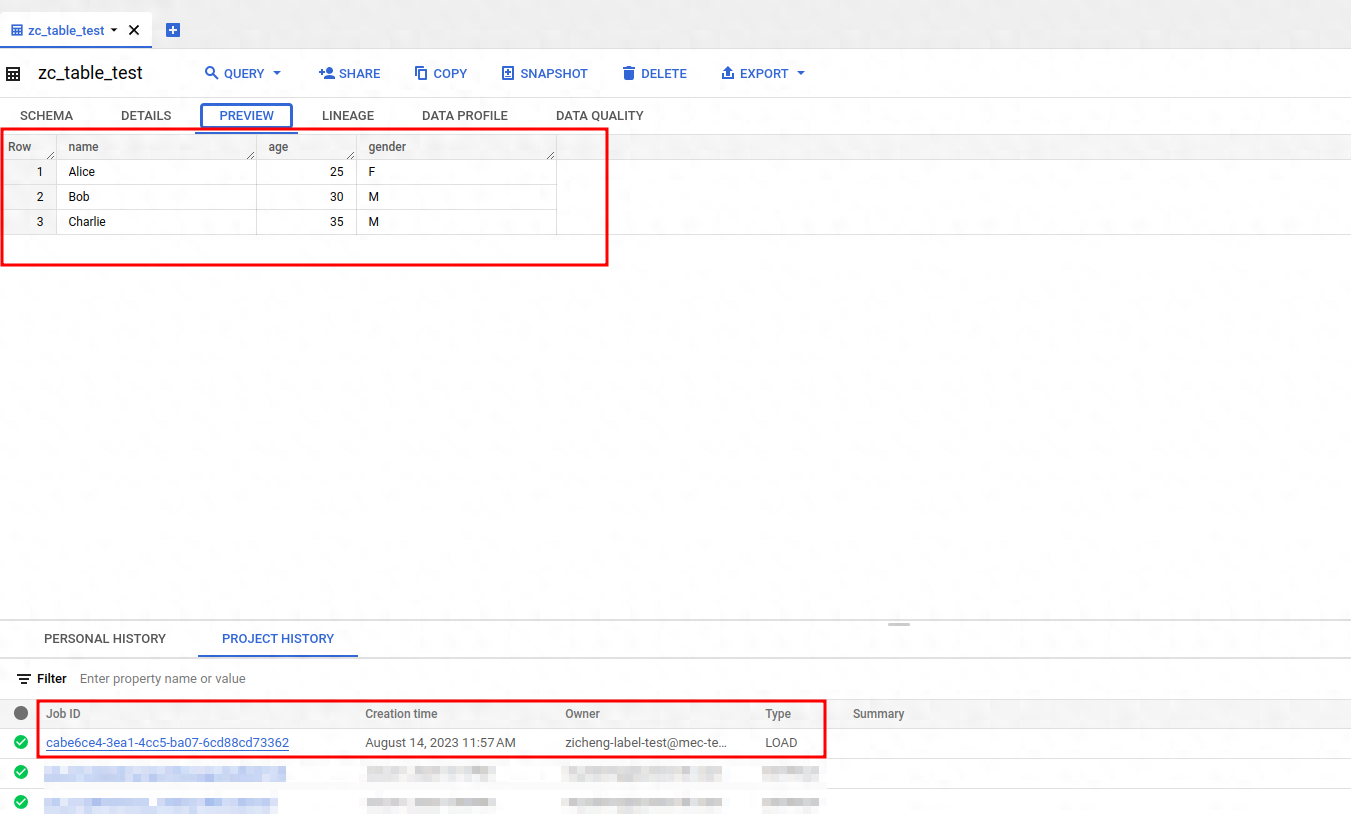
我们可以在project history查看导入数据任务成功的记录,并预览Table的数据做验证,可以看到extra字段的数据没有被导入。
故障排查
直接使用load_table_from_dataframe
由于load_table_from_dataframe不支持source_format=
bigquery.SourceFormat.NEWLINE_DELIMITED_JSON
会收到如下报错:
- ValueError: Got unexpected source_format: ‘NEWLINE_DELIMITED_JSON’. Currently, only PARQUET and CSV are supported
或者不定义SourceFormat时收到如下报错:
- google.api_core.exceptions.BadRequest: 400 POST https://bigquery.googleapis.com/upload/bigquery/v2/projects/mec-test-344202/jobs?uploadType=multipart: Provided Schema does not match Table mec-test-344202:zicheng_test.zc_table_test. Cannot add fields (field: extra)
拓展方案
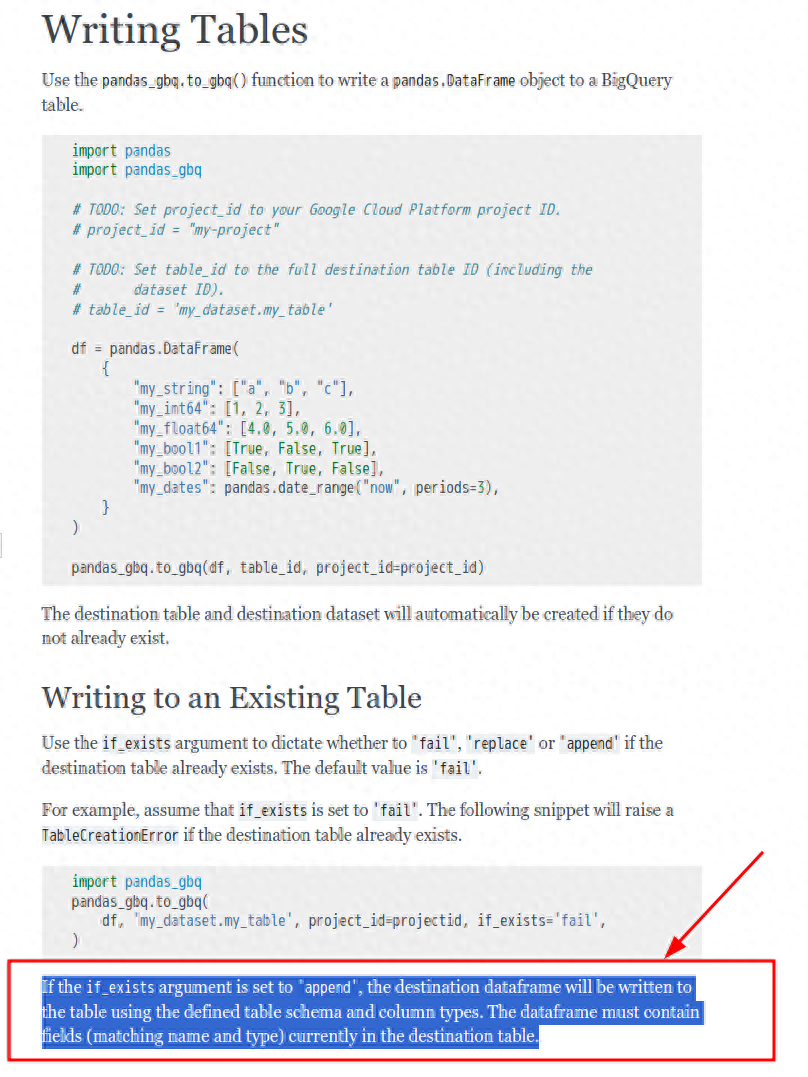
使用第三方库pandas-gbq[4]
参考文档
[1]https://cloud.google.com/bigquery/docs/access-control?hl=zh-cn
[2]https://cloud.google.com/bigquery/docs/control-access-to-resources-iam?hl=zh-cn#grant_access_to_a_resource
[3]https://cloud.google.com/bigquery/docs/reference/rest/v2/Job#JobConfigurationLoad.FIELDS.ignore_unknown_values
[4]https://googleapis.dev/python/pandas-gbq/latest/writing.html#writing-to-an-existing-table