作者:MeshCloud脉时云公有云架构师 于文宝
引言:
产品优势:
快速进行流式数据分析
Dataflow 可实现快速、简化的流式数据流水线开发,且数据延迟时间更短。
简化运营和管理
Dataflow 的无服务器方法消除了数据工程工作负载的运营开销,让团队可以专注于编程,而不必管理服务器集群。
降低总体拥有成本
资源自动扩缩功能搭配费用优化的批处理功能,使得 Dataflow 可提供几乎无限的容量来管理季节性和峰值工作负载,而不会让您过度开支。
目标事件:
Pub/Sub Topic to BigQuery 模板是一种流处理流水线,可从 Cloud Pub/Sub 主题读取 JSON 格式的消息并将其写入 BigQuery 表格中
在您的 Google Cloud 项目中启用 Dataflow 和其他所需的 API。

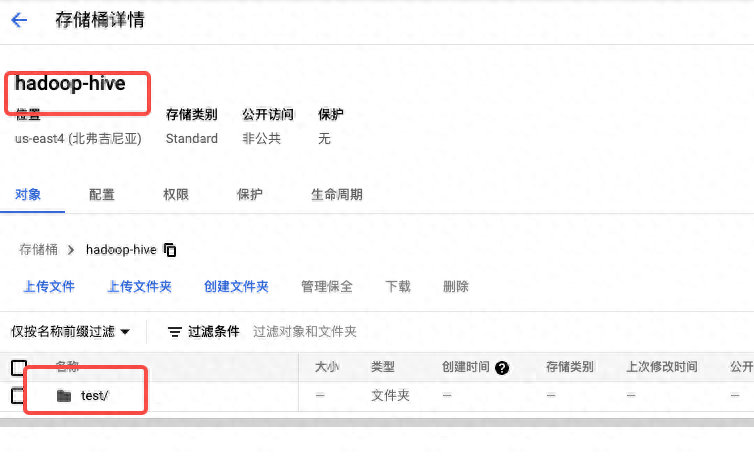
创建对象存储痛
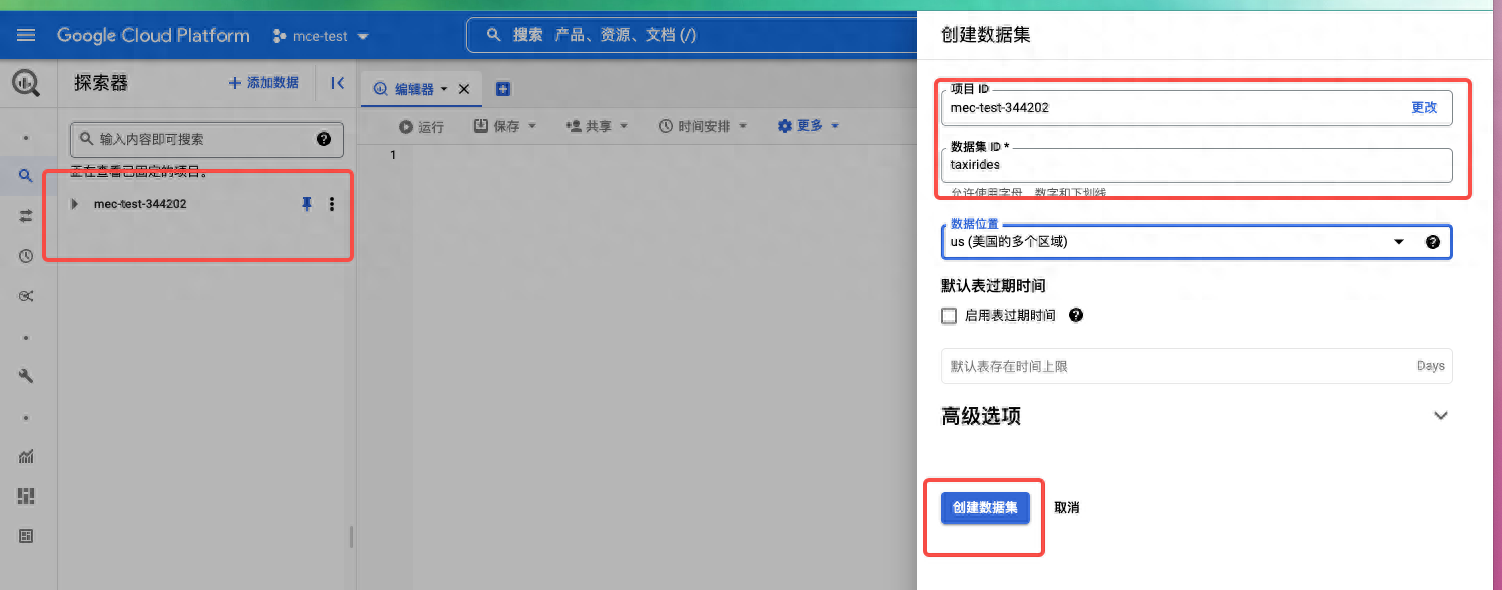
创建 BigQuery 数据集
- 对于数据集 ID,输入 taxirides。
- 对于数据位置,选择 us (multiple regions in the United States)(美国 [美国的多个区域])
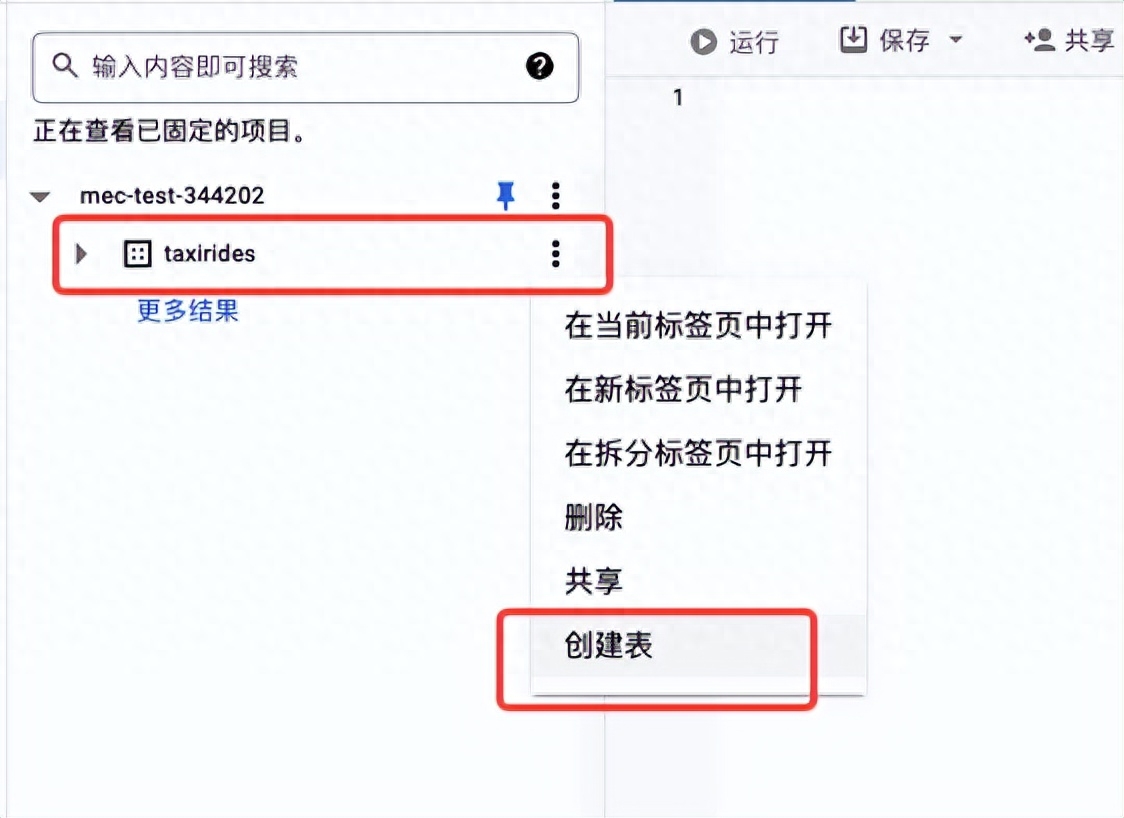
创建 BigQuery 表
- 点击 taxirides 数据集旁边的 查看操作,然后点击打开。
- 在详细信息面板中,点击创建表
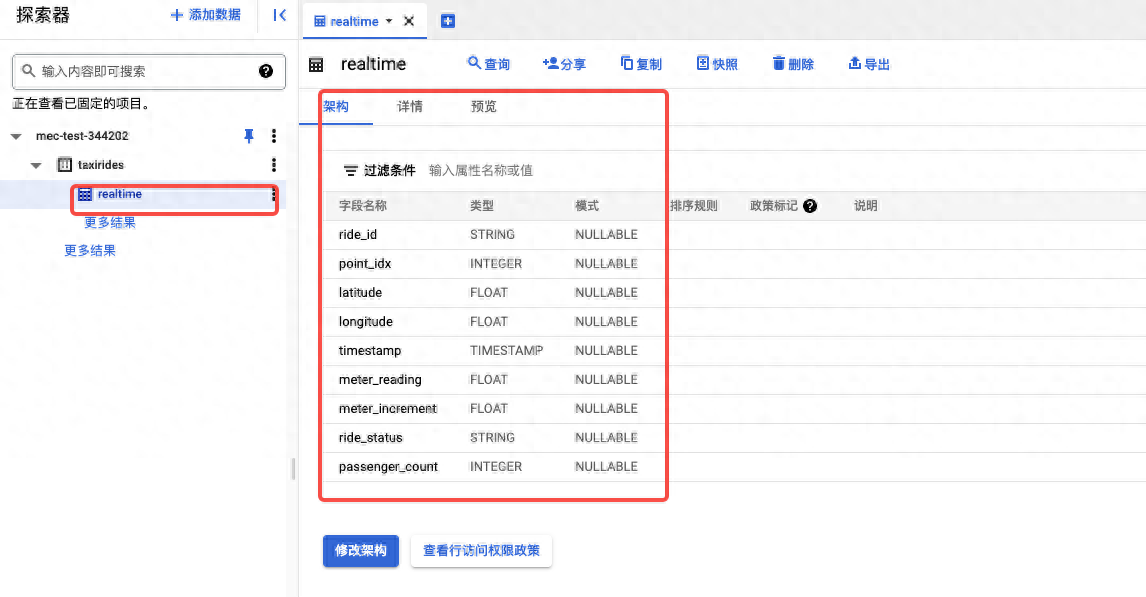
- 在架构部分,点击以文本形式修改切换开关 已文本形式修改字段ride_id:string,point_idx:integer,latitude:float,longitude:float,timestamp:timestamp, meter_reading:float,meter_increment:float,ride_status:string,passenger_count:integer
- 在 Partitioning and cluster settings(分区和集群设置)部分中,对于分区,选择时间戳字段
运行流水线
- 前往 Dataflow 作业页面。
- 点击基于模板创建作业。
- 输入 taxi-data 作为 Dataflow 作业的名称
- 对于 Dataflow 模板,选择 Pub/Sub Topic to BigQuery 模板。
- 创建topic projects/pubsub-public-data/topics/taxirides-realtime对于此公开提供的 Pub/Sub 主题基于纽约市出租车和豪华轿车委员会的开放数据集。以下是来自此主题的 JSON 格式的示例消息:
{
"ride_id": "19c41fc4-e362-4be5-9d06-435a7dc9ba8e",
"point_idx": 217,
"latitude": 40.75399,
"longitude": -73.96302,
"timestamp": "2021-03-08T02:29:09.66644-05:00",
"meter_reading": 6.293821,
"meter_increment": 0.029003782,
"ride_status": "enroute",
"passenger_count": 1
}- BigQuery 输出表,输入以下内容mec-test-344202:taxirides.realtime
- 对于临时位置,输入以下内容 gs://BUCKET_NAME/temp/将 BUCKET_NAME 替换为您的 Cloud Storage 存储桶的名称
- 命令行创建:
gcloud dataflow jobs run taxi-data --gcs-location gs://dataflow-templates-us-central1/latest/PubSub_to_BigQuery --region us-central1 --staging-location gs://hadoop-hive/test/ --parameters inputTopic=projects/pubsub-public-data/topics/taxirides-realtime,outputTableSpec=mec-test-344202:taxirides.realtime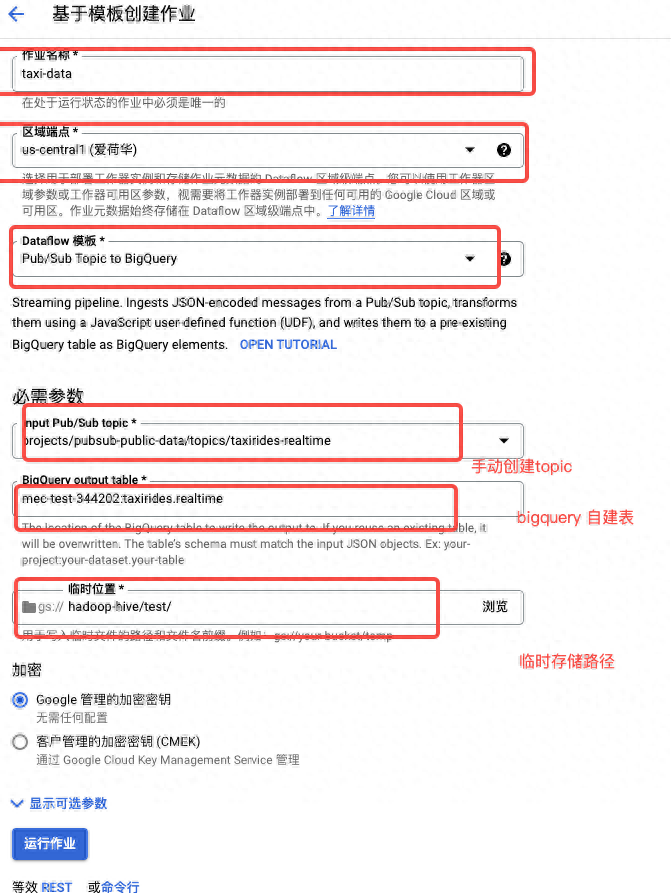
执行过程如图:

查看结果
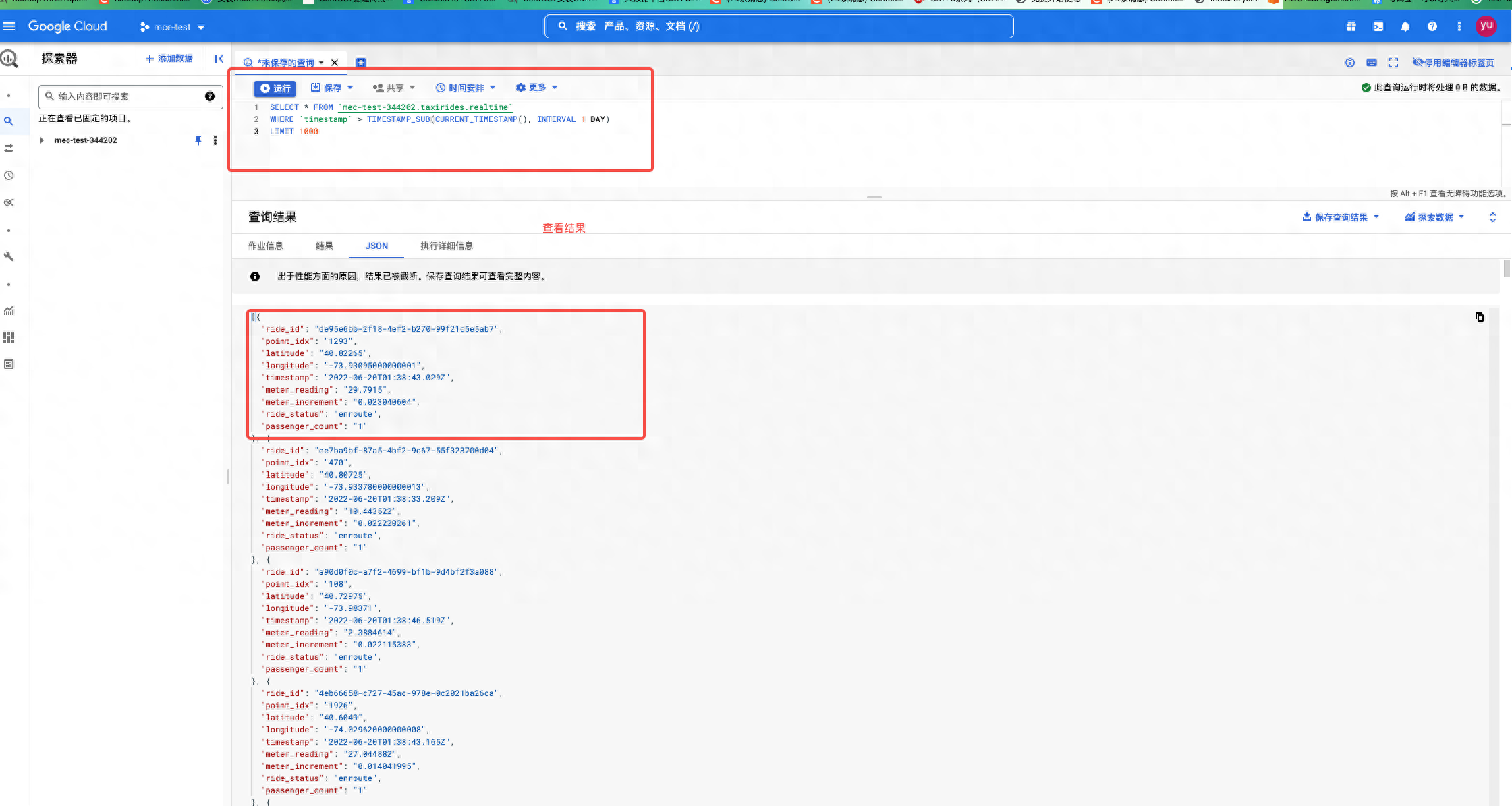
- 前往 BigQuery。去查询结果
- 查询sql :SELECT * FROM `mec-test-344202.taxirides.realtime` WHERE `timestamp` > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) LIMIT 1000
问题补充:
BigQuery 创建表需要提前创建表的字段和分区,以时间时间戳查询结果