作者:MeshCloud脉时云公有云架构师周宽
本文介绍了如何将本地 PostgreSQL 集群迁移到 Google Cloud。此方法使用 PgBouncer 作为连接池程序,这可以最大限度地减少应用停机时间,并有助于设置用于监控结果的工具。本文的目标受众是在 Linux 环境中工作的 PostgreSQL 管理员和系统管理员。
在下图中,PgBouncer 实例位于本地主实例的前面。
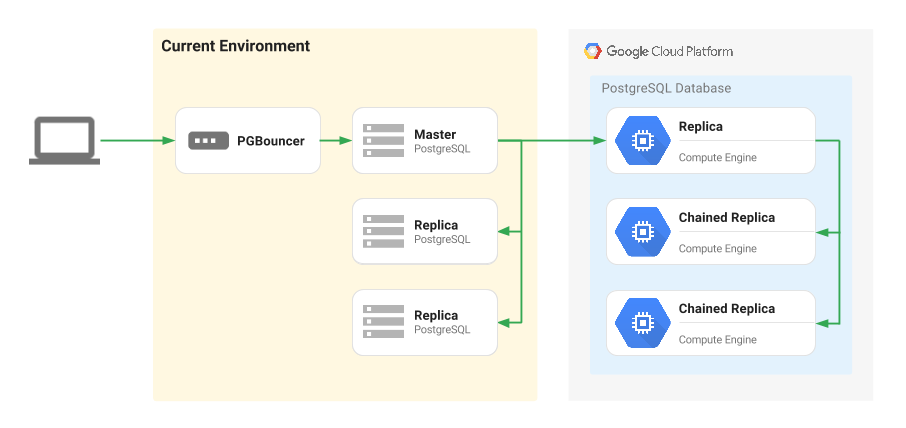
有了连接池,客户端便会在故障切换到 Google Cloud 时路由到替代节点,而无需重新部署应用配置或进行应用级更改。
下图演示了迁移过程。
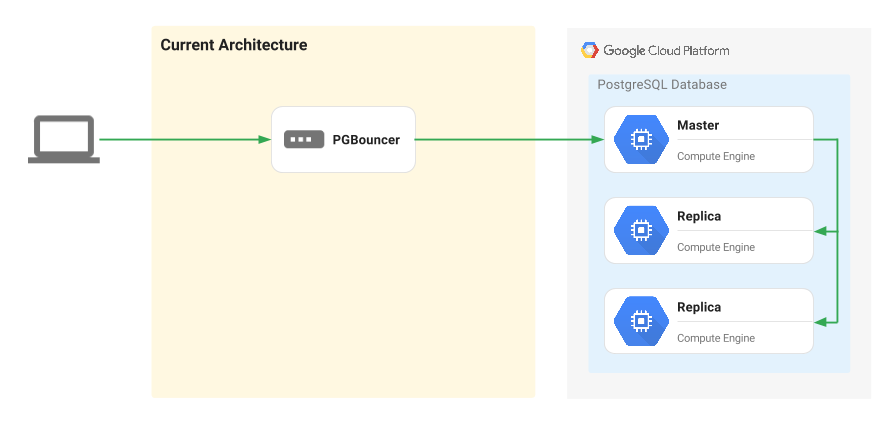
如需执行迁移,请关停当前主实例,然后将从属 Google Cloud 副本提升为主实例。PgBouncer 会将流量重新路由到 Google Cloud 上的新主节点。
一、目标
- 在 Google Cloud 中设置 PostgreSQL。
- 在 Compute Engine 上设置复制功能。
- 将数据播种 (seed) 至新实例。
- 在 Google Cloud 上设置 PostgreSQL 集群。
- 切换到新服务器。
- 实现监控功能。
二、准备工作
- 登录您的 Google Cloud 帐号。
- 选择或创建一个Google Cloud 项目。
- 确保项目已启用结算功能。
- 启用 Compute Engine API。
- Google Cloud 控制台启动 Cloud Shell。
本教程使用 gcloud 和 gsutil 命令,您可以在通过 Google Cloud 控制台启动的 Cloud Shell 实例中运行这些命令。如果要在本地工作站上使用 gcloud 和 gsutil,请安装 Google Cloud CLI。
三、设置环境
首先执行以下任务:
- 在 Google Cloud 中设置 PostgreSQL。
- 在 Compute Engine 上设置复制功能。
然后,在开始复制主实例之前,将数据播种到新实例。
3.1 在 Google Cloud 中设置 PostgreSQL
请按照如何设置 PostgreSQL 以通过热备用模式实现高可用性和复制功能中所述的步骤操作,只需几分钟即可在 Google Cloud 上设置好 PostgreSQL。您可在 Compute Engine 上的 Ubuntu 虚拟机实例中配置 PostgreSQL。
3.2 在 Compute Engine 上设置复制功能
请按照如何在 Google Compute Engine 上设置 PostgreSQL 中所述的步骤配置 PostgreSQL,使其在 Compute Engine 上以热备用模式运行。您需要使用两个 Compute Engine 实例。一个实例用于运行主 PostgreSQL 服务器,另一个实例用于运行备用服务器。
尽管用于配置 PostgreSQL 的属性在主实例和从属实例之间有所不同,但属性文件应当相同,以便实现无缝故障切换。
PostgreSQL 集群中的从属实例通过 recovery.conf 文件的存在来表示。
在大多数情况下,都有必要分离数据库的数据目录与启动磁盘。在本例中,数据库文件存储在 /database 处装载的目录中。
如需修改主实例上的 postgresql.conf 文件以设置复制功能,请使用以下命令:
wal_level = 'hot_standby'
archive_mode = on
archive_command = 'test ! -f /postgresql/archivedir/%f && cp %p /postgresql/archivedir/%f'
max_wal_senders = 3
listen_addresses = '*'
wal_keep_segments = 8如需修改副本上的 postgresql.conf 文件,请使用以下命令:
hot_standby = on
standby_mode = on
primary_conninfo = 'host=${PRIMARY_IP} port=5432 user=repuser'向副本发送 Read 请求可以减轻主实例的负载。
3.3 播种数据
由于主数据库有事务日志限额,因此大多数 PostgreSQL 迁移都需要将数据种子设定为新实例,然后才能开始复制主实例。可通过以下某种方式播种数据:
- 使用 Pg_dump 将单个数据库转储为一个脚本或归档文件。
- 使用 Pg_basebackup 获取正在运行的数据库集群的二进制副本。
- 使用 rsync 将数据文件夹复制到副本。
- 将旧备份恢复到副本。
在上述方式中,推荐的方式是将旧备份恢复到副本。采用这种解决方案时,系统性能不会因传输数据量大而受到影响,并且当前集群仍能够继续正常运行。
在数据库的初始种子设定完成之后,您可以使用 rsync 命令将更改馈送到执行备份后生成的副本;该命令会同步两个实例之间的数据目录。如果备份比主实例滞后太多,无法通过正常复制与之同步,那么这步操作非常重要。
四、在 Google Cloud 上设置 PostgreSQL 集群
您可以使用级联复制功能创建 PostgreSQL 集群。首先迁移数据库,如下图所示。
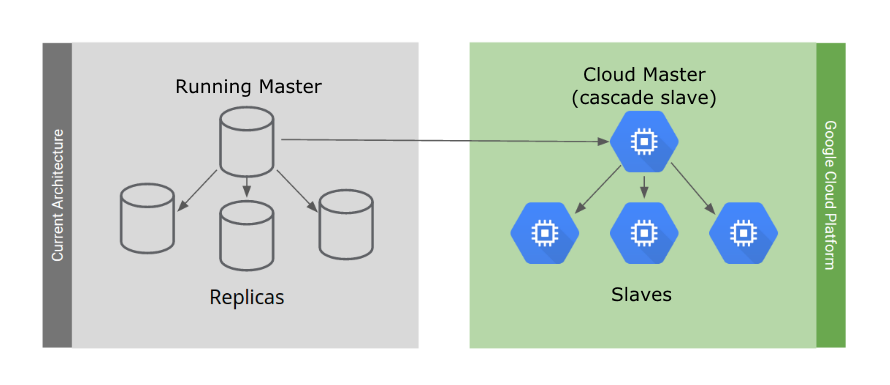
4.1 迁移数据库
- 从正在运行的主服务器获取完整备份(label 可以是任何标签):
echo "select pg_start_backup('label',true);" |sudo su - postgres -c psql
sudo tar cvfz postgresql_AAAAMMDD.tar.gz $PGDATA$PGDATA 是 PostgreSQL 的主数据目录。
- 在 Google Cloud 项目中创建一个名为 gs://pg-repo/ 的存储分区。
- 将备份转移到刚刚创建的存储分区:
master$ gsutil cp postgresql_AAAAMMDD.tar.gz gs://pg-repo/- 将备份文件转移到 Google Cloud 主实例:
new_master$ gsutil cp gs://pg-repo/postgresql_AAAAMMDD.tar.gz- 将备份文件恢复到 Google Cloud 主实例:
new_master$ (cd / ; tar xvf postgresql_AAAAMMDD.tar.gz)- 在 $PG_DATA 目录中创建一个包含以下内容的 recovery.conf 文件:
standby_mode = 'on'
primary_conninfo = 'port=5432 host=${running_master_ip} user=${replication_user} application_name=cloud_master'
trigger_file = '/tmp/failover.postgresql.5432'注意:trigger_file 值可以采用任何名称,并且可以放在您指定的任何目录中。为便于记忆,此示例使用名称 failover.postgresql.5432,该文件旨在对端口 5432 上运行的 PostgreSQL 强制进行故障切换。
- 启动 PostgreSQL 服务:
sudo service postgresql start- 等待 Google Cloud 主服务器与正在运行的主实例同步。在日志中,您可以看到如下所示的内容:
tail -f /var/log/postgresql/postgresql*log
...
2018-09-22 17:59:54 UTC LOG: consistent recovery state reached at 0/230000F0
2018-09-22 17:59:54 UTC LOG: database system is ready to accept read only connections
...注意:0/230000F0 是 pg_xlog ID。您的 ID 会有所不同。
此外,您可以搜索 master pg_stat_replication 来确定新的从属实例(称为 cloud_master)是否已连接:
postgres=# x
Expanded display is on.
postgres=# select * from pg_stat_replication where application_name='cloud_master';
-[ RECORD 1 ]----+------------------------------
pid | 16940
usesysid | 16402
usename | repmgr
application_name | cloud_master
...4.2 创建从属数据库
- 关停数据库和服务器:
sudo service postgresql stop
sudo shutdown -h now- 如需验证服务已经停止,请运行以下命令:
gcloud compute instances describe master-instance-name | grep status在输出中,实例的状态将显示为 TERMINATED:
status: TERMINATED接下来,创建数据磁盘的快照以帮助创建新的从属实例。
- 在 Google Cloud Console 中,转到快照页面。
- 基于 PostgreSQL 磁盘新建一个快照。
- 启动 Google Cloud 主服务器。
- 转到虚拟机实例页面,点击 master-instance-name,然后点击启动。
PostgreSQL 服务即会自动启动。
- 如需检查这一点,请运行以下命令:
ps ax | grep postgres结果应该类似如下所示:
1398 ? S 0:00 /usr/lib/postgresql/9.3/bin/postgres -D /var/lib/postgresql/9.3/main -c config_file=/etc/postgresql/9.3/main/postgresql.conf
1454 ? Ss 0:00 postgres: checkpointer process
1455 ? Ss 0:00 postgres: writer process
1456 ? Ss 0:00 postgres: wal writer process
1457 ? Ss 0:00 postgres: stats collector process- 在 Google Cloud 控制台中,转到虚拟机实例页面,然后点击创建实例。
- 对于启动磁盘,选择 Ubuntu 14.04。
- 点击管理、磁盘、网络、SSH 密钥,然后根据您之前创建的快照添加新的磁盘。
- 启动新服务器并装载该磁盘:
sudo mkdir /database && sudo mount /dev/sdb1 /database- 安装 PostgreSQL:
sudo apt-get install postgresql && sudo service postgresql stop- 配置数据目录和复制值。从 Google Cloud 主实例中复制 postgresql.conf 文件和 pg_hba.conf 文件,然后修改 recovery.conf 文件以包含以下内容:
standby_mode = 'on'
primary_conninfo = 'port=5432 host=${cloud_master_ip} user=${replication_user} application_name=cloud_slave_${identifier}'
recovery_target_timeline = 'latest'- 使用新的配置文件启动 PostgreSQL 服务,使其指向 Google Cloud 主实例:
sudo service postgresql restart- 验证服务正在运行:
ps ax | grep postgres- 使用以下查询检查 Google Cloud 主服务器:
postgres=# x
Expanded display is on.
postgres=# select * from pg_stat_replication where application_name like 'cloud_slave%';
-[ RECORD 1 ]----+-----------------------------
pid | 2466
usesysid | 16402
usename | repmgr
application_name | cloud_slave_1
...- 重复上述步骤来创建更多从属实例。
五、切换到新服务器
- 将 PgBouncer 中的配置文件更改为指向新的 Google Cloud 主服务器。
- 在 PgBouncer 实例中,关停 PgBouncer,使用 failover.postgresql.5432 触发器文件提升新的主实例,然后重启 PgBouncer:
service pgbouncer stop ; ssh ${cloud_master_ip} 'touch /tmp/failover.postgresql.5432' ; service pgbouncer start六、查询示例
检查服务器上的所有并发连接数:
select * from pg_stat_activity;(主实例)检查复制状态:
select * from pg_stat_replication;(主实例)检查副本应用数据的延迟情况:
select pg_xlog_location_diff(write_location, replay_location) from pg_stat_replication;(主实例)检查复制的字节延迟情况:
select client_hostname, client_addr, pg_xlog_location_diff(pg_stat_replication.sent_location,
pg_stat_replication.replay_location)AS byte_lag from pg_stat_replication;(从属实例)检查数据库是否为副本:
select pg_is_in_recovery();(从属实例)检查上次从主实例接收的数据:
select pg_last_xlog_receive_location();(从属实例)检查上次从主实例应用的数据:
select pg_last_xlog_replay_location();(从属实例)检查复制延迟时间(以秒为单位):
select now() - pg_last_xact_replay_timestamp();