作者:MeshCloud脉时云公有云架构师 吴子成
引言
Dataproc 是一项完全托管且高度可扩展的服务,用于在 Google Cloud Platform 上运行 Apache Hadoop、Apache Spark、Apache Flink、Presto 等 30 多个开源工具和框架。 Dataproc 既能利用开源数据处理的强大功能和灵活性,又省去了管理自己的基础设施的麻烦和成本。
Dataproc 提供了许多功能,以支持运行开源数据处理工作负载,具有更灵活的特性。 其中一些功能包括:
• 无服务器部署:Dataproc 支持创建在完全托管的集群上运行的无服务器 Spark 作业,无需任何集群配置或管理。 可以将代码作为 Python 文件或 Jupyter Notebook 提交,然后让 Dataproc 处理其余的工作。
• 容器化:Dataproc 支持使用 GKE 上的 Dataproc 在 Kubernetes 集群上运行 Spark 作业。 这提供了对作业的更多控制和可移植性,并能够利用 Kubernetes 的优势进行编排和扩展。
• 数据科学集成:Dataproc 与 Vertex AI Workbench 集成,后者是一项托管服务,为数据科学和机器学习提供交互式笔记本。 您可以使用 Vertex AI Workbench 在笔记本内的 Dataproc 集群上创建和运行 Spark 作业。 您还可以使用 Vertex AI Workbench 访问其他 Google Cloud AI 服务,例如 BigQuery ML 、 Vertex AI 和 TensorFlow Enterprise 。
• 企业安全性:Dataproc 支持高级安全功能,例如 Kerberos 身份验证、Apache Ranger 授权、静态和传输中加密、VPC 服务控制、客户管理的加密密钥等。 您还可以使用 Dataproc Metastore 以安全且可扩展的方式管理 Hive 元存储或目录服务。
本文引导大家通过GCP python client libraries快速入门 Dataproc ,实现用service account认证,创建Dataproc集群,提交PySpark job,并在job完成后关停集群以节省费用。
准备工作
1) 创建服务帐号并配置IAM权限
要有效、安全地使用 Dataproc,需要了解如何控制用户和组对 Dataproc 资源(例如集群、作业、操作和工作流程模板)的访问权限。 这就是身份和访问管理 (IAM) 的用武之地。
Dataproc 权限是用户(包括服务帐号)可以对 Dataproc 资源执行的操作。 例如,dataproc.clusters.create 权限允许用户在项目中创建 Dataproc 集群。
通常我们遵守最小权限原则,可以根据文档[1]选择合适的权限。为方便演示,本文案例中使用预定义的roles/dataproc.admin。
2) 准备好python环境
本文案例中GCE的操作系统为Centos 7,软件版本为Python 3.6.8和pip 21.3.1
3) 创建GCS桶,并上传PySpark job的脚本
本文案例中job脚本(sort.py)如下
import pyspark
sc = pyspark.SparkContext()
rdd = sc.parallelize(["Hello,", "world!", "dog", "elephant", "panther"])
words = sorted(rdd.collect())
print(words)实施步骤
1) 本文案例的Demo代码
"""
This quickstart sample walks a user through creating a Cloud Dataproc
cluster, submitting a PySpark job from Google Cloud Storage to the
cluster, reading the output of the job and stopping the cluster, all
using the Python client library.
Usage:
python quickstart.py --project_id <PROJECT_ID> --region <REGION>
--cluster_name <CLUSTER_NAME> --job_file_path <GCS_JOB_FILE_PATH>
--key_file_path <Service_Account_KEYFILE_PATH>
"""
import argparse
import re
# Import google.auth library and google.oauth2.service_account module
import google.auth
from google.oauth2 import service_account
from google.cloud import dataproc_v1 as dataproc
from google.cloud import storage
def quickstart(project_id, region, cluster_name, job_file_path, key_file_path):
# Load credentials from key file
credentials = service_account.Credentials.from_service_account_file(
key_file_path
)
# Create the cluster client with the credentials
cluster_client = dataproc.ClusterControllerClient(
client_options={"api_endpoint": "{}-dataproc.googleapis.com:443".format(region)},
credentials=credentials # Pass the credentials
)
# Create the cluster config.
cluster = {
"project_id": project_id,
"cluster_name": cluster_name,
"config": {
"master_config": {"num_instances": 1, "machine_type_uri": "n1-standard-2", "disk_config": {"boot_disk_size_gb": 100}},
"worker_config": {"num_instances": 2, "machine_type_uri": "n1-standard-2", "disk_config": {"boot_disk_size_gb": 100}},
"secondary_worker_config": {"num_instances": 2, "machine_type_uri": "n1-standard-2", "disk_config": {"boot_disk_size_gb": 100}},
},
}
# Create the cluster.
operation = cluster_client.create_cluster(
request={"project_id": project_id, "region": region, "cluster": cluster}
)
result = operation.result()
print("Cluster created successfully: {}".format(result.cluster_name))
# Create the job client with the credentials
job_client = dataproc.JobControllerClient(
client_options={"api_endpoint": "{}-dataproc.googleapis.com:443".format(region)},
credentials=credentials # Pass the credentials
)
# Create the job config.
job = {
"placement": {"cluster_name": cluster_name},
"pyspark_job": {"main_python_file_uri": job_file_path},
}
operation = job_client.submit_job_as_operation(
request={"project_id": project_id, "region": region, "job": job}
)
response = operation.result()
# Dataproc job output gets saved to the Google Cloud Storage bucket
# allocated to the job. Use a regex to obtain the bucket and blob info.
matches = re.match("gs://(.*?)/(.*)", response.driver_output_resource_uri)
output = (
storage.Client()
.get_bucket(matches.group(1))
.blob(f"{matches.group(2)}.000000000")
.download_as_bytes().decode("utf-8")
)
print(f"Job finished successfully: {output}")
# Update a cluster with the new number of secondary workers
update_mask = {"paths": ["config.secondary_worker_config.num_instances"]}
cluster = {
"project_id": project_id,
"cluster_name": cluster_name,
"config": {
"secondary_worker_config": {
"num_instances": 0
}
}
}
# Update the cluster
operation = cluster_client.update_cluster(
project_id=project_id, region=region, cluster_name=cluster_name, cluster=cluster, update_mask=update_mask)
result = operation.result()
# Output a success message
print('Cluster updated successfully: {}'.format(result.cluster_name))
# Stop the cluster
request = dataproc.StopClusterRequest(
project_id=project_id,
region=region,
cluster_name=cluster_name
)
operation = cluster_client.stop_cluster(request=request)
result = operation.result()
print('Cluster stoped successfully: {}'.format(result.cluster_name))
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description=__doc__, formatter_class=argparse.RawDescriptionHelpFormatter,
)
parser.add_argument(
"--project_id",
type=str,
required=True,
help="Project to use for creating resources.",
)
parser.add_argument(
"--region",
type=str,
required=True,
help="Region where the resources should live.",
)
parser.add_argument(
"--cluster_name",
type=str,
required=True,
help="Name to use for creating a cluster.",
)
parser.add_argument(
"--job_file_path",
type=str,
required=True,
help="Job in GCS to execute against the cluster.",
)
parser.add_argument(
"--key_file_path",
type=str,
required=True,
help="Path of service account.",
)
args = parser.parse_args()
quickstart(args.project_id, args.region, args.cluster_name, args.job_file_path, args.key_file_path)2) 执行代码做验证
python3 quickstart.py --project_id mec-test-344202 --region europe-west3 --cluster_name zc-dataproc --job_file_path "gs://zicheng-bucket/sort.py" --key_file_path "/root/zicheng.json"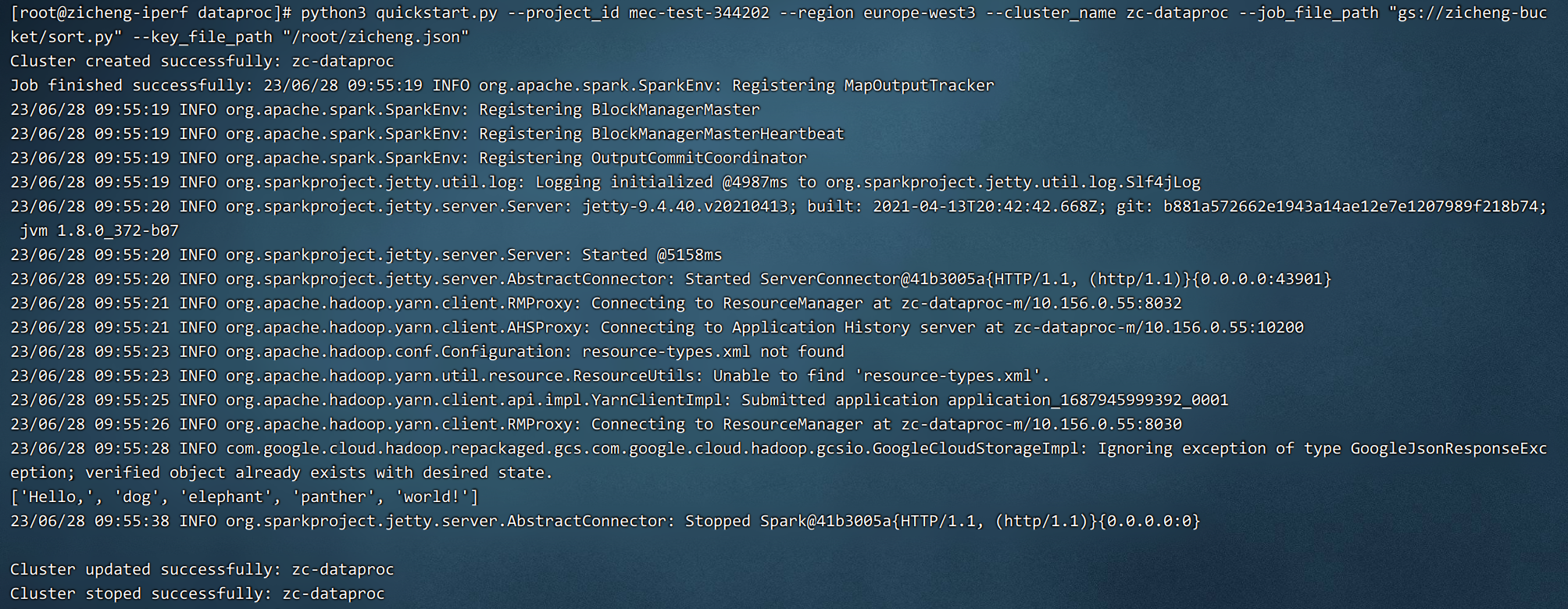
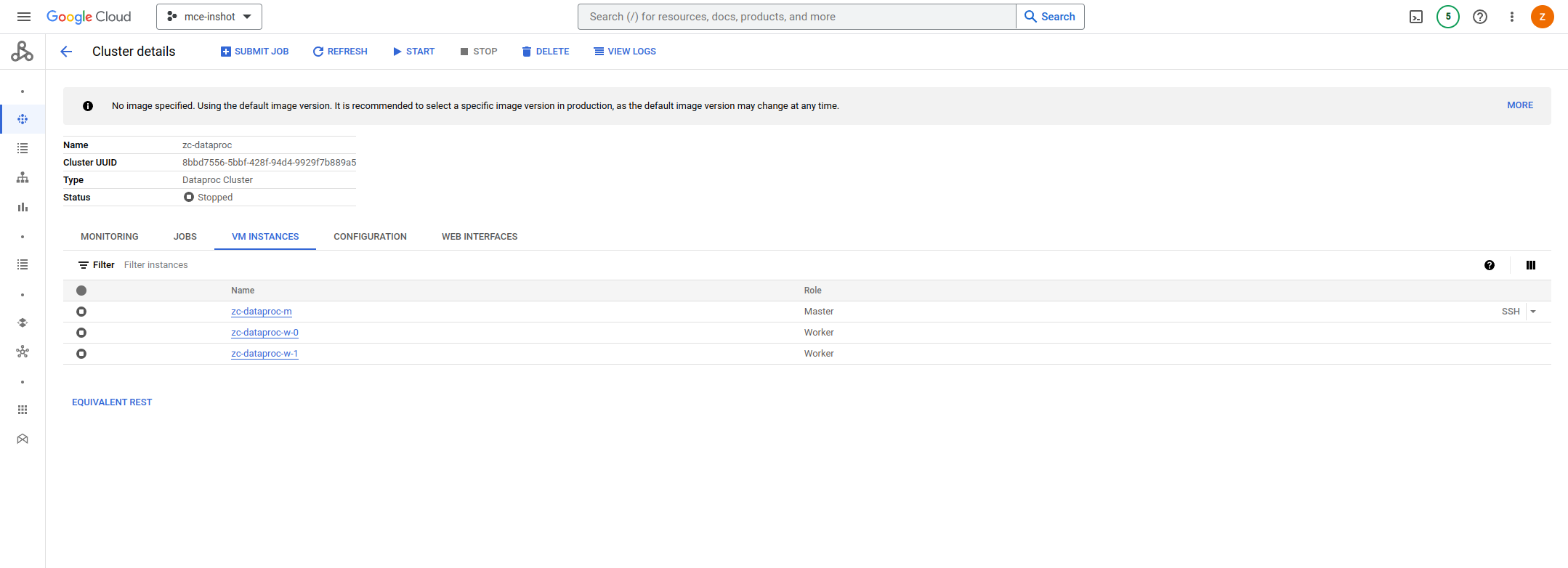
对应在控制台中的变化如下:
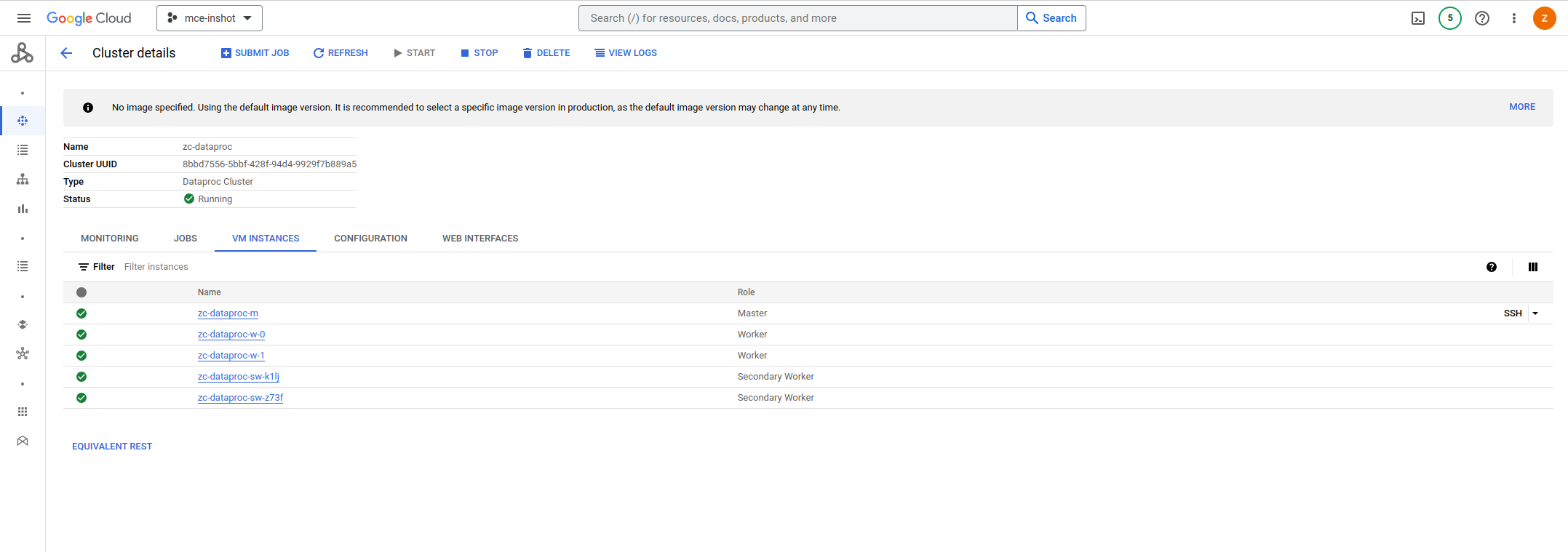
a.创建集群并拉起资源

b.集群的VM INSTANCES全部为running状态
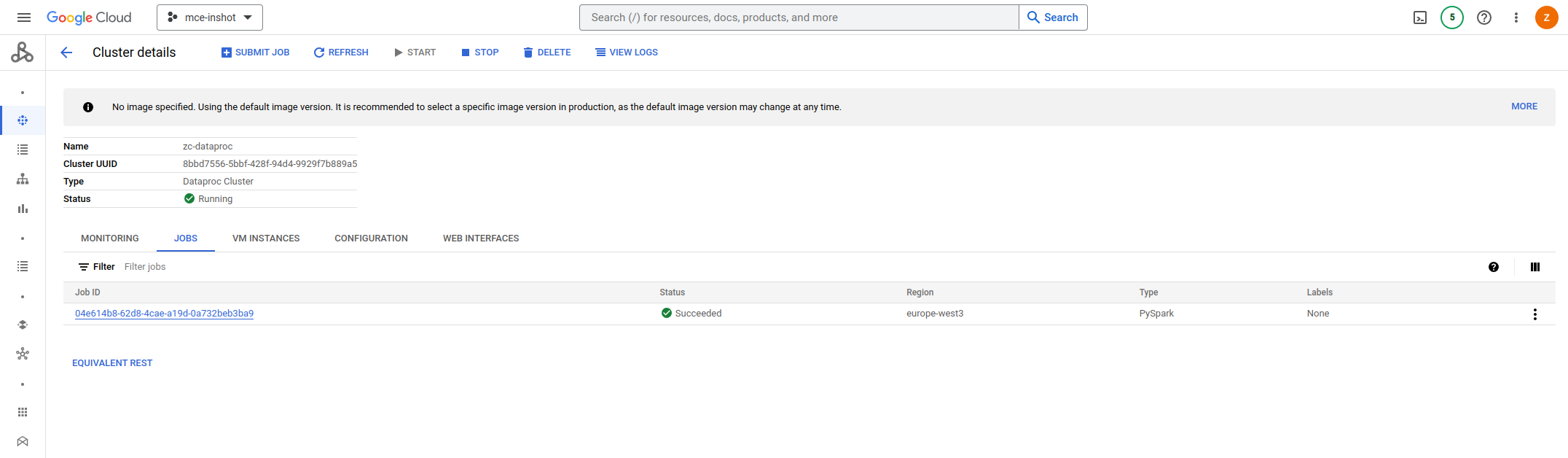
c.从GCS提交PySpark job到Dataproc集群
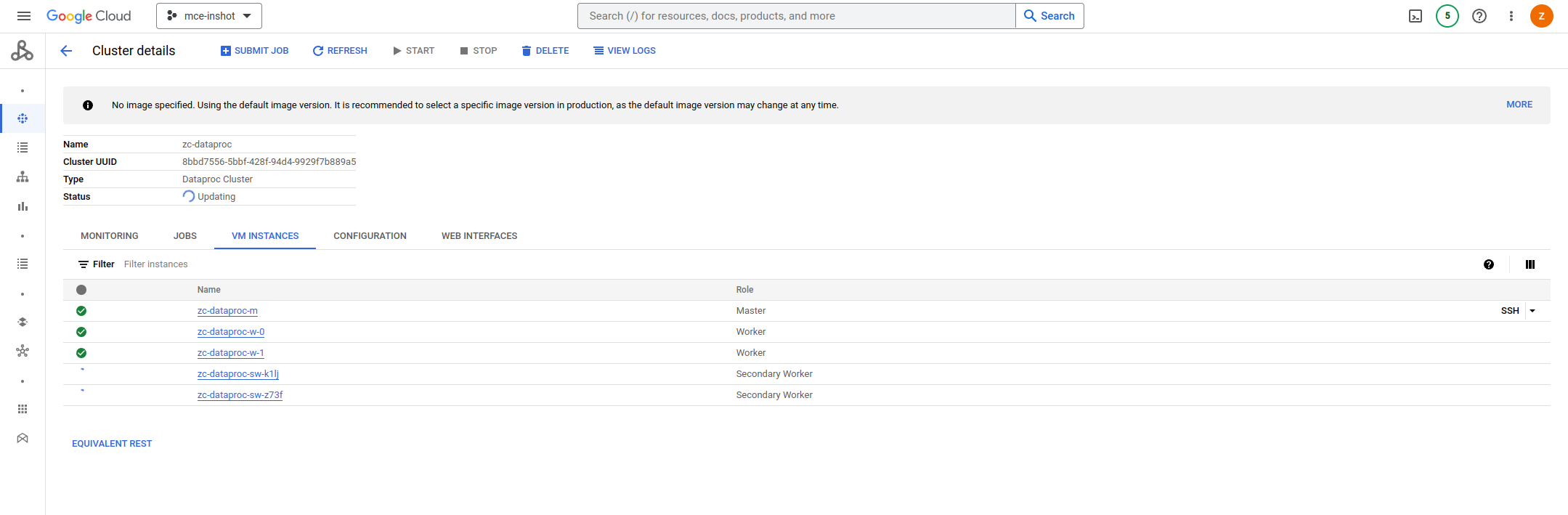
d.需要注意的是,如果使用了secondary workers,在关停集群前需要把secondary workers的数量更新为0
e.任务执行完成后,关停集群节省成本
参考文档
[1]https://cloud.google.com/dataproc/docs/concepts/iam/iam
[2]https://cloud.google.com/dataproc/docs/samples/dataproc-quickstart?hl=en#dataproc_quickstart-python
[3]https://cloud.google.com/python/docs/reference/dataproc/latest