Amazon Bedrock is a fully managed service that provides access to Foundation Models (FMs) from third-party providers and Amazon. With Bedrock, you can choose from a variety of models to find the one that best suits your needs.
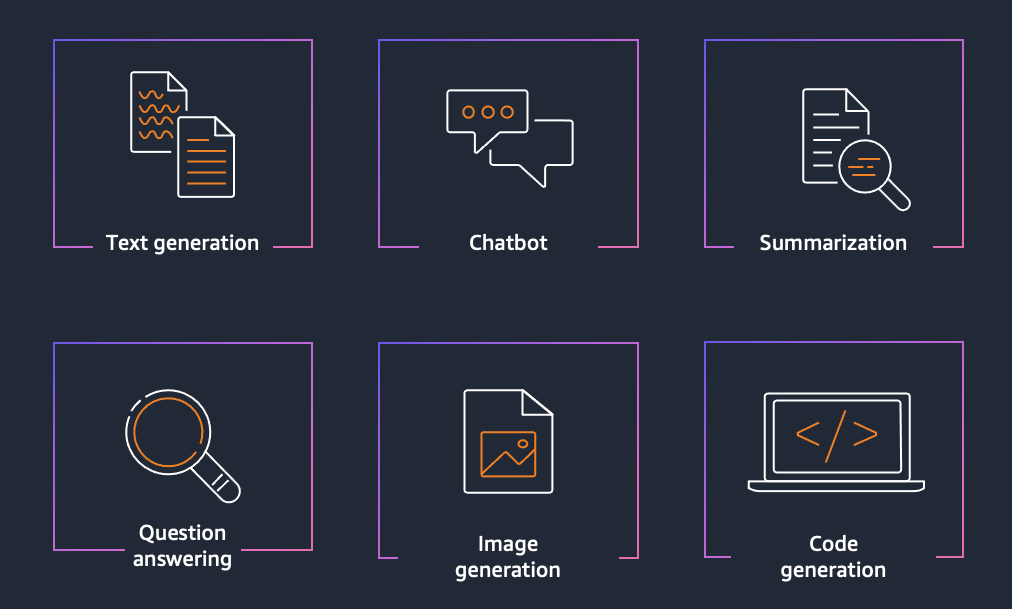
Its usage scenarios include the following:
1. InvokeModel vs. Converse
There are two primary ways to call models in the Amazon Bedrock Runtime API: InvokeModel and the Converse API (which includes CreateConversation and ConversationInvokeStream for session management).

InvokeModel
- Characteristics: Single request-response pattern; stateless; suitable for all supported models.
- Use Cases:
- Single queries or tasks, such as text generation, question answering, or summarization.
- Tasks that do not require context memory.
- Batch processing or parallel processing of multiple independent requests.
- Simple API integration.
- Example Uses:
- Generating product descriptions.
- Answering standalone questions.
- Text classification or sentiment analysis.
- Code generation or debugging.
Converse API
- Characteristics: Multi-turn conversational mode; maintains conversation state and context; supports streaming responses; currently only available for specific models (e.g., Anthropic’s Claude).
- Use Cases:
- Applications requiring continuous conversation.
- Scenarios where the model needs to remember previous interactions.
- Applications needing real-time, streaming responses.
- Complex, multi-step tasks.
- Example Uses:
- Customer service chatbots.
- Interactive teaching assistants.
- Multi-turn question-answering systems.
- Collaborative writing or programming assistants.
Converse vs. ConverseStream
Converse and ConverseStream are two different API call methods, with the main difference being how responses are handled.
- Converse API:
- A synchronous call that returns the complete response at once.
- Suitable for short conversations or scenarios that do not require real-time feedback.
- ConverseStream API:
- An asynchronous, streaming call that returns partial responses as they are generated.
- Ideal for long conversations or interactive scenarios requiring immediate feedback.
Recommendations
- Use
InvokeModelwhen: You need to handle independent, unrelated requests, and your application does not need to maintain a conversational state. - Use
Conversewhen: You are building a conversational application, need the model to remember previous interactions, and want to receive streaming, real-time responses.
Note that while InvokeModel does not directly support multi-turn dialogues, you can simulate this functionality by managing the conversation history at the application level and including the relevant context in each API call. This method, while flexible, may be less efficient than using the dedicated Converse API.
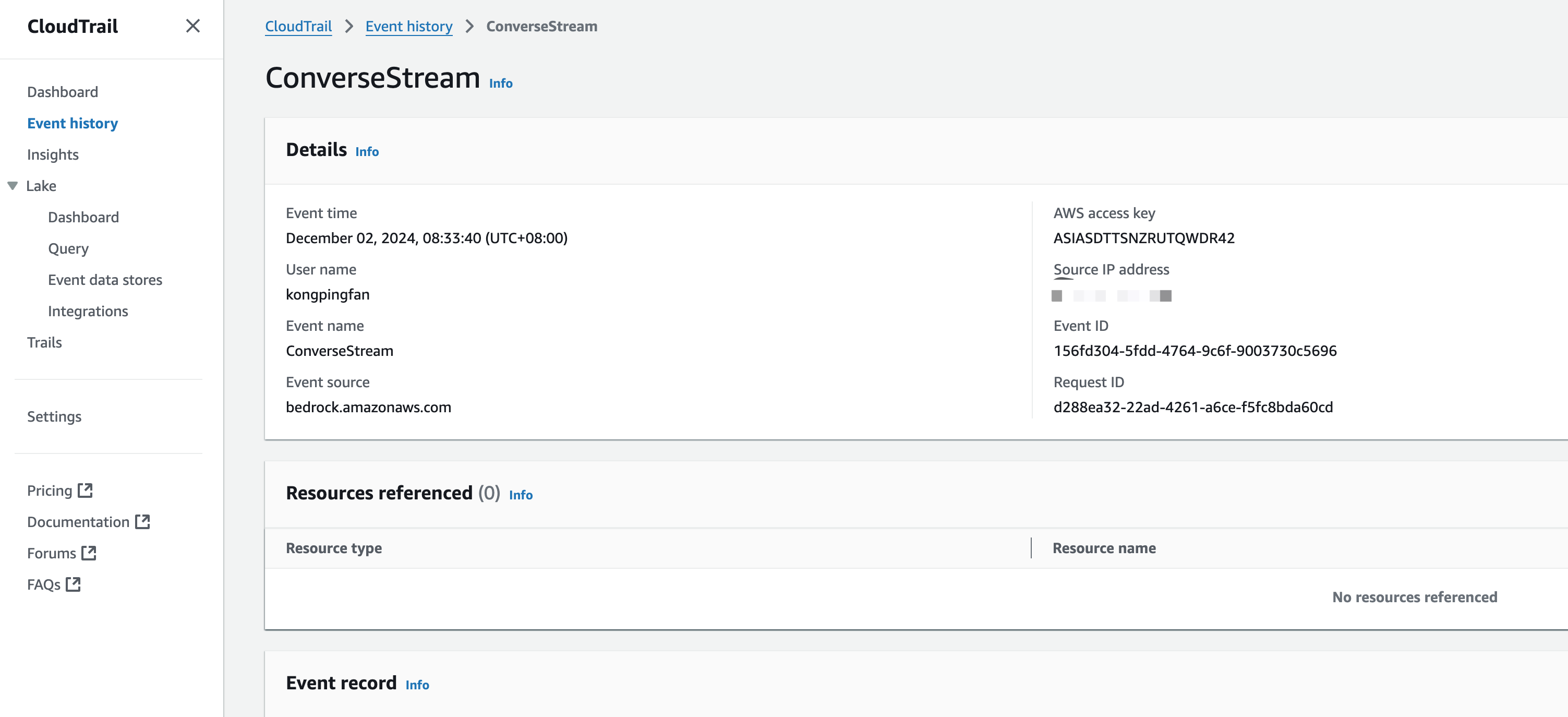
CloudTrail Logging
Both InvokeModel and Converse API calls are recorded in AWS CloudTrail.
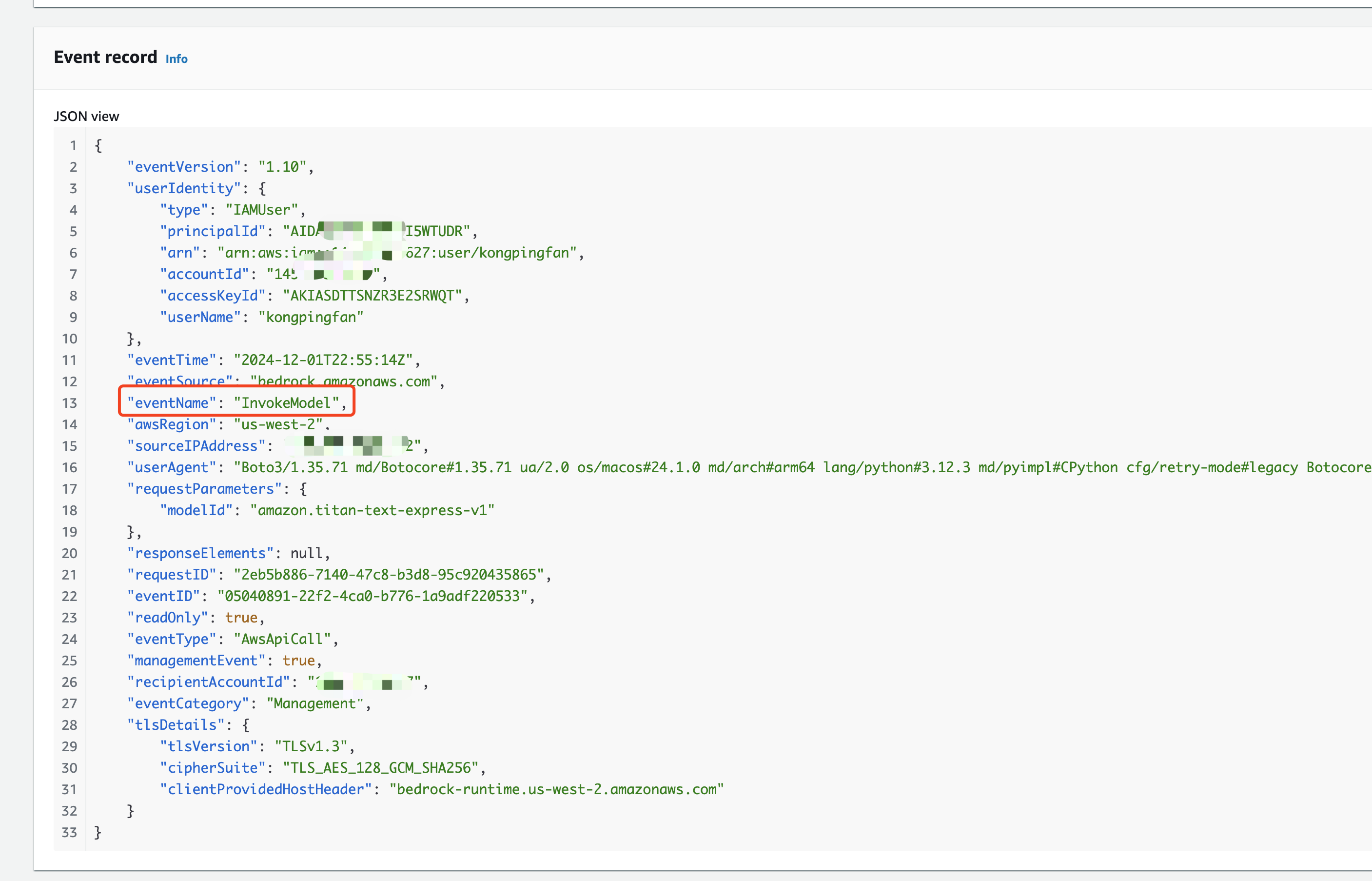
However, the logs do not record the user’s input or the prompt itself; they only record whether the call was successful and the reason for any failures.
When asking a question in the Bedrock Playground, the ConverseStream API is called.
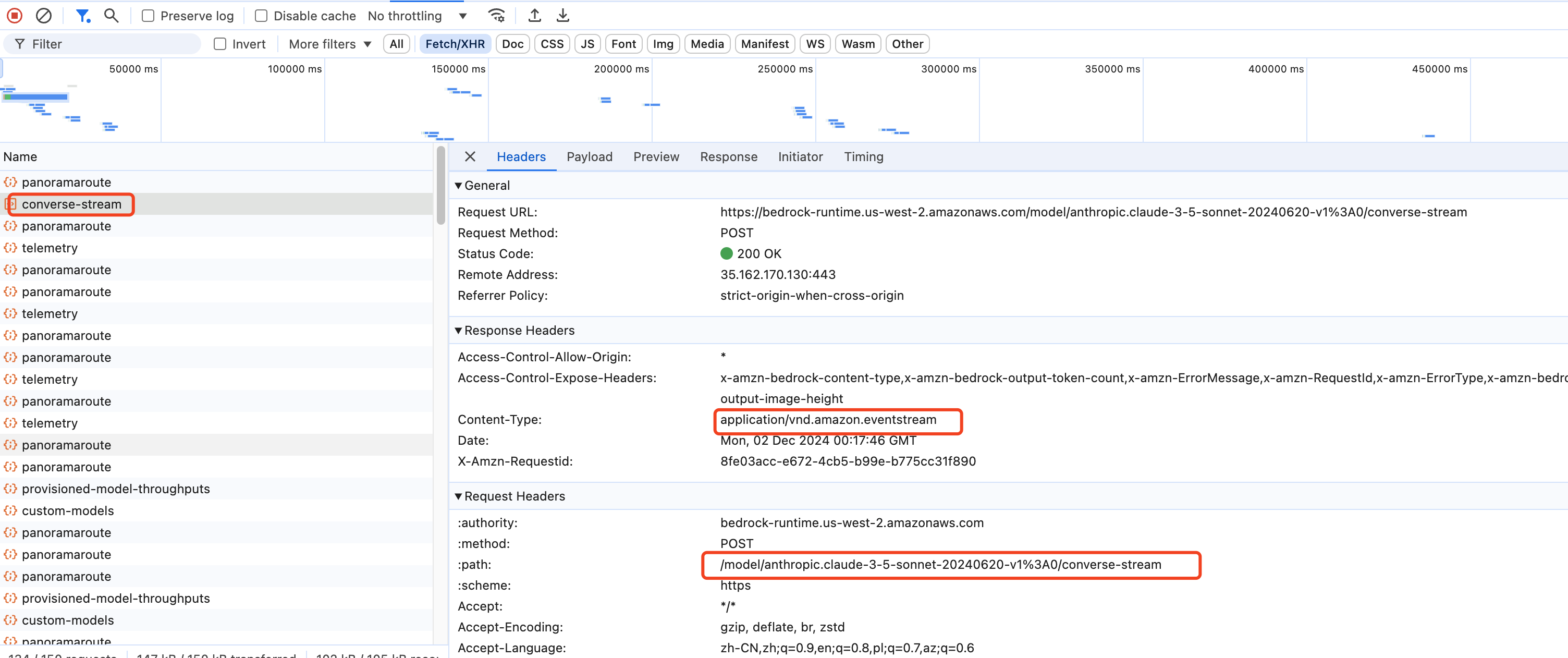
The payload includes the history of questions and answers, and the response is an event stream.
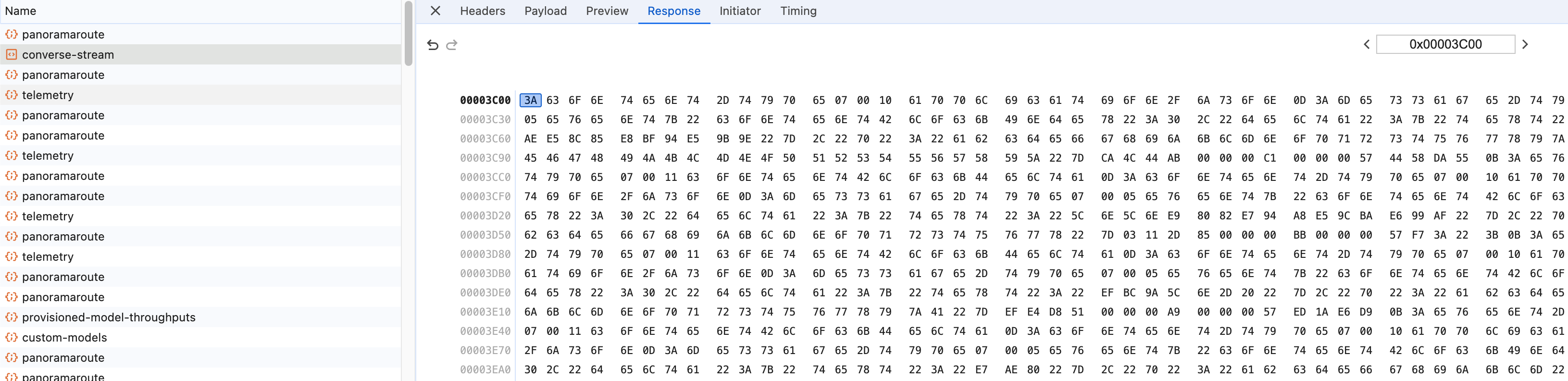
This event is also visible in CloudTrail logs.
2. Text Generation I: Basic Generation
Checking Model Parameters
Different models may require different parameter names. You can find these on the Bedrock Provider page by selecting a provider and then a specific model.
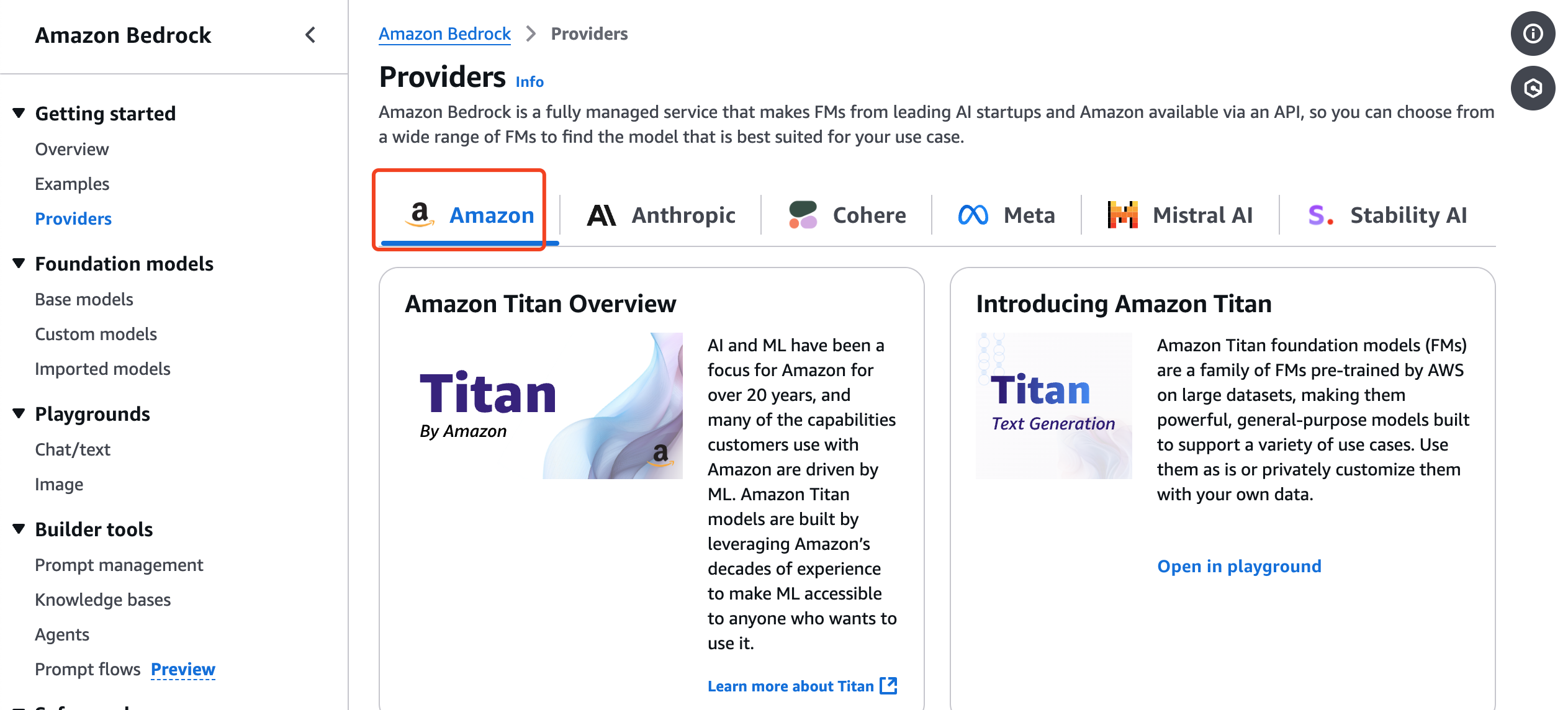
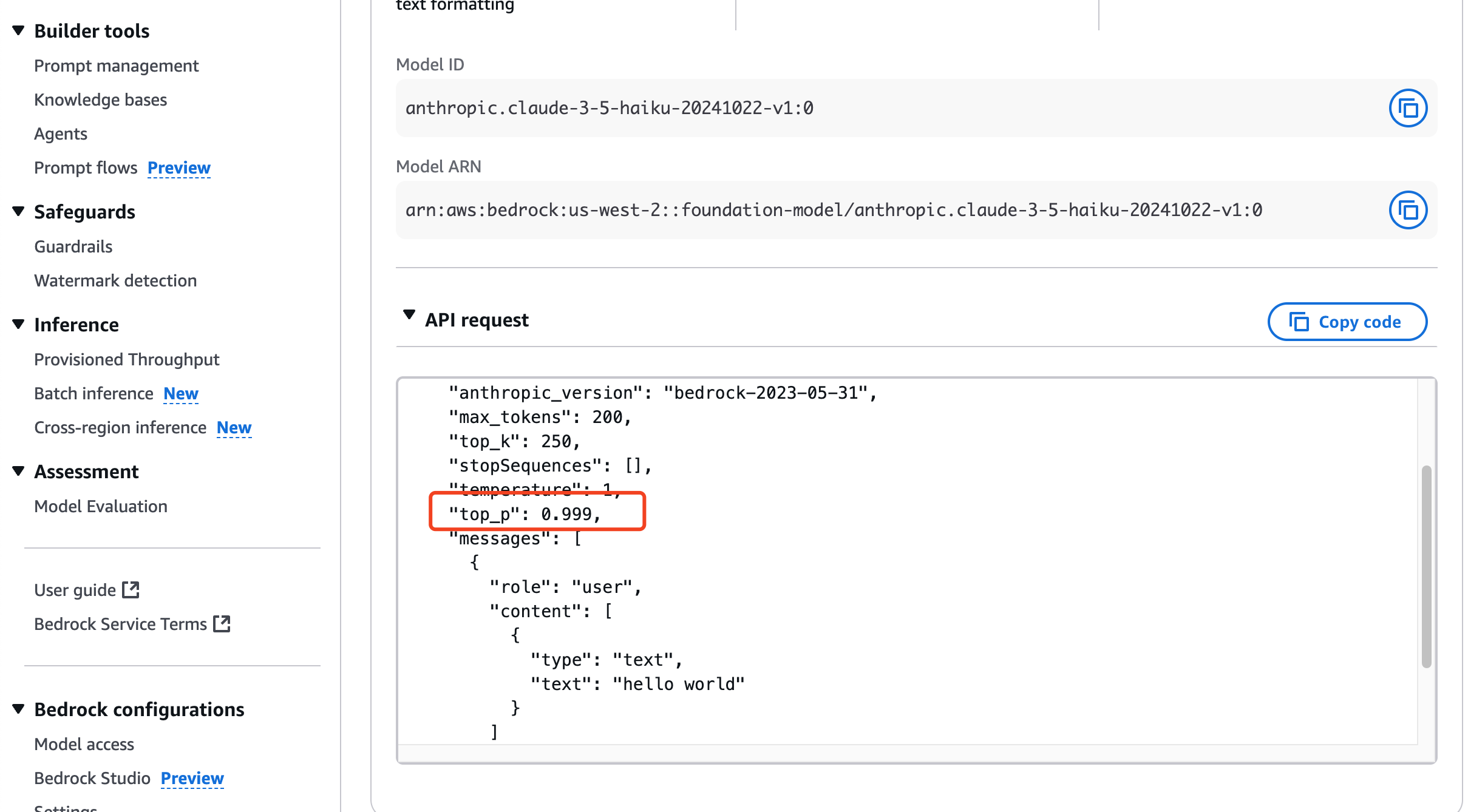
For example, the Titan model requires the topP parameter, whereas an Anthropic Haiku model uses top_p.
Example: Text Generation with Titan
The following Python code demonstrates how to generate text using the amazon.titan-text-express-v1 model.Python
import boto3
import json
def generate_text_with_bedrock(prompt, model_id="amazon.titan-text-express-v1"):
"""
Generates text using AWS Bedrock's Titan Express model.
:param prompt: The user's input prompt.
:param model_id: The model ID to use, default is Titan Express.
:return: The generated text.
"""
# Initialize the Bedrock client
client = boto3.client("bedrock-runtime", region_name="us-west-2")
# Define the generation payload
payload = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 500, # Maximum number of tokens to generate
"temperature": 0.7, # Controls the randomness of the text
"topP": 0.9, # Controls the diversity of the text
"stopSequences": [] # Defines stop sequences
}
}
try:
# Invoke the Bedrock service
response = client.invoke_model(
modelId=model_id,
body=json.dumps(payload),
contentType="application/json"
)
# Parse the response
result = response["body"].read().decode("utf-8")
return result
except Exception as e:
print("Error invoking Bedrock model:", str(e))
return None
# Example usage
prompt = "Write a short story about a brave knight and a dragon."
generated_text = generate_text_with_bedrock(prompt)
if generated_text:
print("Generated Text:")
print(generated_text)
3. Text Generation II: Zero-shot vs. Context-aware
Large Language Models (LLMs) can be used for text generation tasks like creating emails, stories, and social media posts. However, the generated text can sometimes be generic or contain hallucinations.
There are two primary modes for text generation:
- Zero-shot: The user provides an input request without any context or examples.
- Context-aware: The user provides the LLM with contextual information along with the prompt.
Zero-shot Generation
In this example, we will generate an email response to a customer using only a zero-shot prompt.
Using the Boto3 SDK
The invoke_model API in the Boto3 SDK for Amazon Bedrock accepts parameters such as modelId, accept, contentType, and a body containing the prompt and configuration.Python
import json
import boto3
import botocore
boto3_bedrock = boto3.client('bedrock-runtime')
# Create the prompt
prompt_data = """
Command: Write an email from Bob, Customer Service Manager, to the customer "John Doe"
who provided negative feedback on the service provided by our customer support
engineer"""
# The body for Amazon Titan includes the inputText and textGenerationConfig
body = json.dumps({
"inputText": prompt_data,
"textGenerationConfig": {
"topP": 0.95,
"temperature": 0.1
}
})
modelId = 'amazon.titan-text-express-v1'
accept = 'application/json'
contentType = 'application/json'
try:
response = boto3_bedrock.invoke_model(
body=body,
modelId=modelId,
accept=accept,
contentType=contentType
)
response_body = json.loads(response.get('body').read())
outputText = response_body.get('results')[0].get('outputText')
print(outputText)
except botocore.exceptions.ClientError as error:
if error.response['Error']['Code'] == 'AccessDeniedException':
print(f"x1b[41m{error.response['Error']['Message']}n")
else:
raise error
Using LangChain with Amazon Bedrock
LangChain is a framework for developing applications powered by language models. It abstracts the Bedrock API, making it easier to build use cases by simply passing a prompt.Python
from langchain.llms.bedrock import Bedrock
import boto3
boto3_bedrock = boto3.client('bedrock-runtime')
inference_modifier = {
"max_tokens_to_sample": 4096,
"temperature": 0.5,
"top_k": 250,
"top_p": 1,
"stop_sequences": ["nnHuman"],
}
textgen_llm = Bedrock(
model_id="anthropic.claude-v2",
client=boto3_bedrock,
model_kwargs=inference_modifier,
)
# LangChain abstracts the API call
response = textgen_llm("""
Human: Write an email from Bob, Customer Service Manager,
to the customer "John Doe" that provided negative feedback on the service
provided by our customer support engineer.
Assistant:""")
print(response)
Creating a LangChain PromptTemplate
A PromptTemplate allows you to pass different input variables at runtime, which is useful for generating content dynamically.Python
from langchain.prompts import PromptTemplate
# Create a prompt template with multiple input variables
multi_var_prompt = PromptTemplate(
input_variables=["customerServiceManager", "customerName", "feedbackFromCustomer"],
template="""
Human: Create an apology email from the Service Manager {customerServiceManager} to {customerName} in response to the following feedback that was received from the customer:
<customer_feedback>
{feedbackFromCustomer}
</customer_feedback>
Assistant:"""
)
# Pass values to the input variables
prompt = multi_var_prompt.format(
customerServiceManager="Bob",
customerName="John Doe",
feedbackFromCustomer="""Hello Bob,
I am very disappointed with the recent experience I had when I called your customer support.
I was expecting an immediate call back but it took three days for us to get a call back.
The first suggestion to fix the problem was incorrect. Ultimately the problem was fixed after three days.
We are very unhappy with the response provided and may consider taking our business elsewhere.
"""
)
response = textgen_llm(prompt)
email = response[response.index('n')+1:]
print(email)
4. Text Summarization I: Basic Summarization
Text summarization is a Natural Language Processing (NLP) technique for extracting the most relevant information from a document and presenting it concisely. This is achieved by sending a prompt to a model with an instruction to summarize a given text.
Key challenges include managing documents that exceed token limits and obtaining high-quality summaries.
Example: Text Summarization with Prompts
Here we will send a small amount of text data to the Amazon Bedrock API with an instruction to summarize it. We will use both Amazon Titan and Anthropic Claude models.Python
# Using Amazon Titan
import json
import boto3
import botocore
boto3_bedrock = boto3.client('bedrock-runtime')
prompt = """
Please provide a summary of the following text. Do not add any information that is not mentioned in the text below.
<text>
AWS took all of that feedback from customers, and today we are excited to announce Amazon Bedrock,
a new service that makes FMs from AI21 Labs, Anthropic, Stability AI, and Amazon accessible via an API.
Bedrock is the easiest way for customers to build and scale generative AI-based applications using FMs,
democratizing access for all builders. Bedrock will offer the ability to access a range of powerful FMs
for text and images—including Amazons Titan FMs, which consist of two new LLMs we’re also announcing
today—through a scalable, reliable, and secure AWS managed service. With Bedrock’s serverless experience,
customers can easily find the right model for what they’re trying to get done, get started quickly, privately
customize FMs with their own data, and easily integrate and deploy them into their applications using the AWS
tools and capabilities they are familiar with, without having to manage any infrastructure (including integrations
with Amazon SageMaker ML features like Experiments to test different models and Pipelines to manage their FMs at scale).
</text>
"""
body = json.dumps({
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 1024,
"stopSequences": [],
"temperature": 0,
"topP": 1
},
})
modelId = 'amazon.titan-tg1-large'
accept = 'application/json'
contentType = 'application/json'
try:
response = boto3_bedrock.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
print(response_body.get('results')[0].get('outputText'))
except botocore.exceptions.ClientError as error:
# ... error handling ...
raise error
5. Text Summarization II: Using LangChain for Large Documents
When dealing with large documents, we face challenges like exceeding the model’s context length, model hallucinations, and out-of-memory errors. To address this, we can split the document into smaller chunks and process them sequentially.
LangChain supports several methods for this, such as map_reduce, where each chunk is summarized individually, and then the summaries are combined and summarized again.
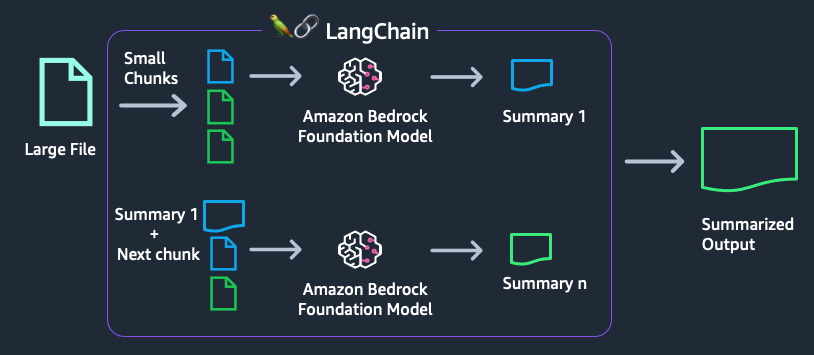
This example uses the map_reduce method to summarize a large text file.Python
import boto3
from langchain.llms.bedrock import Bedrock
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
from io import StringIO
import sys
import textwrap
boto3_bedrock = boto3.client('bedrock-runtime')
# Initialize the LLM
modelId = "amazon.titan-tg1-large"
llm = Bedrock(
model_id=modelId,
model_kwargs={
"maxTokenCount": 4096,
"temperature": 0,
"topP": 1,
},
client=boto3_bedrock,
)
# Load the document
with open("2022-letter.txt", "r") as file:
letter = file.read()
# Split the document into chunks
text_splitter = RecursiveCharacterTextSplitter(
separators=["nn", "n"], chunk_size=4000, chunk_overlap=100
)
docs = text_splitter.create_documents([letter])
# Load and run the summarization chain
summary_chain = load_summarize_chain(llm=llm, chain