Cloud Bigtable 是一种流行且被广泛使用的键值数据库,可在 Google Cloud 上使用。该服务提供规模弹性、成本效率、出色的性能特征和 SLA 99.999% 的可用性。成千上万的客户信任 Bigtable,用它来运行各种关键任务工作负载。
Bigtable 有超过 15 年的应用历史。它在峰值时每秒处理超过 50 亿个请求,并且管理着超过 10 EB 的数据。它是 Google 最大的半结构化数据存储服务之一。
Google Bigtable 的关键用例之一是广告个性化,它在广告个性化中扮演着核心角色。
# 广告个性化 #
广告个性化旨在通过呈现主题性和相关性的广告内容来提升用户体验。例如,我经常在 YouTube 上观看制作面包的视频。如果在我的广告设置中启用了广告个性化,我的观看历史可能会向 YouTube 表明我有兴趣将烘焙作为主题,并且可能会对与烘焙产品相关的广告内容感兴趣
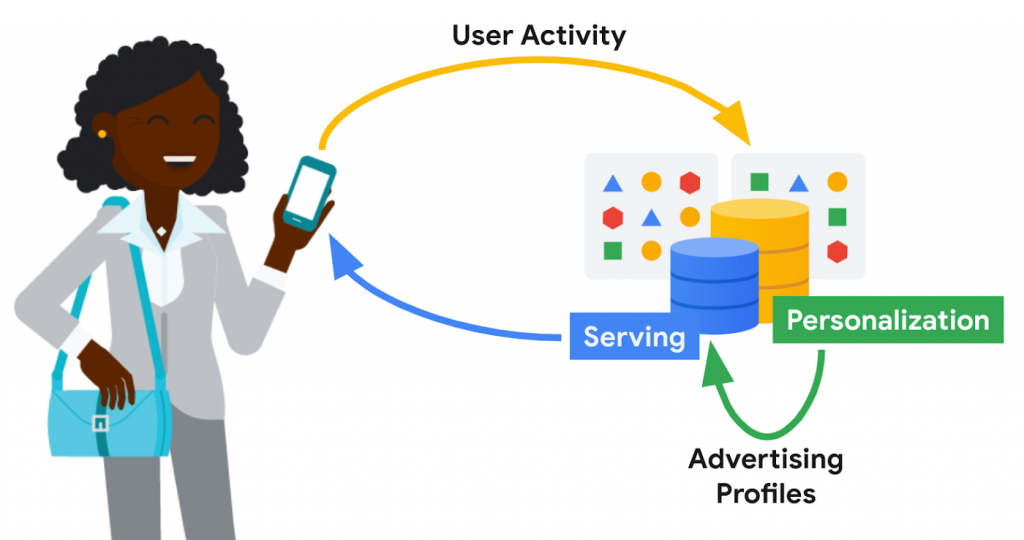
广告个性化需要近乎实时的大规模数据处理,严格地控制用户数据的处理和保留,以便呈现及时个性化展示。系统可用性需要很高,并且服务延迟需要很低,以满足在狭窄的窗口内决定检索和提供哪些广告内容。次优的服务决策(例如退回到通用广告内容)可能会影响用户体验。广告经济学要求将基础设施成本保持在尽可能低的水平。谷歌的广告个性化平台提供了开发和部署机器学习模型的框架,用于广告内容的相关性展示和排名,支持实时和批量个性化。该平台使用 Bigtable 构建,允许 Google 产品以符合隐私和政策的安全方式访问数据源来进行广告个性化,同时尊重用户希望向 Google 提供哪些数据的决定。个性化管道的输出(例如广告配置文件)存储回 Bigtable 以供进一步使用。广告服务堆栈检索这些广告配置文件以推动下一组广告服务决策。个性化平台的一些存储要求包括:
- 非常高的批量访问和近乎实时的个性化
- 在广告投放的关键路径上查找读取低延迟(在 p99 时小于 20 毫秒)
- 快速(例如以秒为单位)增量更新广告模型,以减少个性化延迟
# Bigtabe #Bigtable 的灵活性使其非常适合广告工作负载,表现在支持低成本、高吞吐量的离线个性化数据访问,且在线数据服务访问方面持续的低延迟表现。 Google 规模的个性化需要非常大的存储空间。Bigtable 完全满足给定性能曲线所需的可扩展性、性能一致性和低成本。
数据模型个性化平台将对象存储在 Bigtable 中,作为由对象 ID 键入的序列化 protobuf。在 p99 时,典型数据大小小于 1 MB,服务延迟小于 20 毫秒。 数据被组织为语料库,对应于不同的数据类别。语料库映射到复制的 Bigtable。在语料库中,数据被组织为 DataTypes,即数据的逻辑分组。特征、嵌入和不同风格的广告配置文件存储为 DataTypes,映射到 Bigtable 列族。DataTypes 在描述数据的原型结构和指示所有权和出处的附加元数据的模式中定义。子类型映射到 Bigtable 列并且是自由格式的。 每行数据都由一个基于对象 ID 的 RowID 唯一标识。个性化 API 通过 RowID(行键)、DataType(列族)、SubType(列部分)和时间戳来识别各个值。
一致性操作的默认一致性模式是最终的。在这种模式下,从离用户最近的 Bigtable 副本中检索数据,提供最低的中值和尾部延迟。对单个 Bigtable 副本的读取和写入是一致的。如果一个区域有多个 Bigtable 副本,跨区域的流量溢出的可能性更大。为了提高写后读一致性的可能性,个性化平台使用行亲和性的概念。如果一个区域中有多个副本,则根据 Row ID 的 hash 优先为任何给定行选择一个副本。 对于一致性要求更严格的查找,平台首先尝试从最近的副本中读取,并请求 Bigtable 返回每个副本的当前低水位线 (LWM)。如果最近的副本恰好是发起写入的副本,或者如果 LWM 指示复制已赶上必要的时间戳,则服务将返回一致的响应。如果复制没有赶上,那么服务会发出第二次查找——这次查找的目标是写入发起的 Bigtable 副本。该副本可能很远,请求可能很慢。在等待响应时,平台可能会向其他副本发出故障转移查找,以防复制赶上这些副本。
Bigtable 复制广告个性化工作负载使用具有 20 多个副本的 Bigtable 复制拓扑,分布在四大洲。 复制有助于解决广告服务的高可用性需求。Bigtable 的区域每月正常运行时间百分比超过 99.9%,复制加上多集群路由策略可达到超过 99.999% 的可用性。跨越全球的拓扑允许将数据放置在靠近用户的位置,从而最大限度地减少服务延迟。然而,它也带来了挑战,例如网络链接成本和吞吐量的可变性。Bigtable 使用基于最小生成树的路由算法和节省带宽的代理副本来帮助降低网络成本。 对于广告个性化,减少 Bigtable 复制延迟是降低个性化延迟的关键。更快的复制是首选,但我们还需要平衡服务流量与复制流量,并确保低延迟用户数据服务不会因传入或传出复制流量而中断。在底层,Bigtable 实现了复杂的流量控制和优先级提升机制来管理全局流量并平衡服务和复制流量的优先级。
工作负载隔离广告个性化批量工作负载通过将一组给定的工作负载固定到某些副本上而与服务工作负载隔离;一些 Bigtable 副本专门驱动个性化管道,而另一些则驱动用户数据服务。该模型允许在服务系统和离线个性化管道之间建立连续且近乎实时的反馈循环,同时防止两个工作负载相互竞争。对于 Cloud Bigtable 用户,AppProfiles 和集群路由策略提供了一种将工作负载限制和固定到特定副本以实现粗粒度隔离的方法。
数据驻留默认情况下,数据会复制到每个副本(通常分布在全球范围内),这对于仅在区域内访问的数据来说是一种浪费。区域化通过将数据限制在最有可能被访问的区域来节省存储和复制成本。遵守规定与某些主题有关的数据物理存储在给定地理区域内的法规也很重要。数据的位置可以由请求的访问位置或通过位置元数据和其他产品信号隐式确定。一旦确定了用户的位置,它就会存储在位置元数据表中,该表指向应该将读取请求路由到的 Bigtable 副本。基于行放置策略的数据迁移发生在后台,没有停机时间或服务性能回归。
# 结论 #
在这篇博文中,我们研究了如何在 Google 中使用 Bigtable 来支持一个重要的用例——为广告个性化建模用户意图。 在过去十年中,Bigtable 的规模随着 Google 的个性化需求增长了几个数量级而扩展。对于大规模个性化工作负载,Bigtable 提供具有出色性能特征的低成本存储。它通过简单的用户配置无缝处理全球流量。它易于处理低延迟服务和高吞吐量批处理计算,使其成为 lambda 式数据处理管道的绝佳选择。Google 将继续推动高水平的投资,以进一步降低成本、提高性能并带来新功能,使 Bigtable 成为个性化工作负载的更好选择。