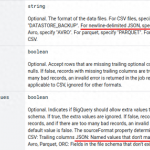
在当今信息时代,数据处理和分析正变得越来越重要。Google BigQuery作为一种强大的云端数据仓库解决方案,以其高速、弹性和易用性备受欢迎。与此同时,数据科学家和分析师们通常倾向于使用Python中的DataFrame来处理和操纵数据。本文将介绍如何从DataFrame加载数据至BigQuery,并在此过程中忽略多余字段,从而轻松高效地进行数据处理。
在当今信息时代,数据处理和分析正变得越来越重要。Google BigQuery作为一种强大的云端数据仓库解决方案,以其高速、弹性和易用性备受欢迎。与此同时,数据科学家和分析师们通常倾向于使用Python中的DataFrame来处理和操纵数据。本文将介绍如何从DataFrame加载数据至BigQuery,并在此过程中忽略多余字段,从而轻松高效地进行数据处理。
本文详细介绍在GKE集群中部署Fluent Bit,实现收集Kubernetes日志并存储到Cloud Logging的步骤。文中包括Fluent Bit ConfigMap配置、DaemonSet部署、日志过滤等内容,既概述了背景知识,也提供了详细的操作指导。全文内容丰富系统,可作为实践Fluent Bit进行Kubernetes日志收集的参考指南。
Cloud Data Fusion 是一项全托管式云原生企业数据集成服务,用于快速构建和管理数据流水线。Cloud Data Fusion 网页界面可让您构建可伸缩的数据集成解决方案,以便清理、准备、混合、转移和转换数据,而无需管理基础架构。(Cloud Data Fusion 由开源项目 CDAP 提供支持。)

快速进行流式数据分析
Dataflow 可实现快速、简化的流式数据流水线开发,且数据延迟时间更短。
简化运营和管理
Dataflow 的无服务器方法消除了数据工程工作负载的运营开销,让团队可以专注于编程,而不必管理服务器集群。
降低总体拥有成本
资源自动扩缩功能搭配费用优化的批处理功能,使得 Dataflow 可提供几乎无限的容量来管理季节性和峰值工作负载,而不会让您过度开支。

Google Cloud 全球负载均衡 Google Cloud Load Balancing (GCLB) 作为一个全球分布式软件定义负载均衡,可以将全球各地的网络请求通过谷歌边缘节点和骨干网高效投递到用户在任一 Google Cloud 数据中心部署的后端服务,是使用频率非常高的一个云产品。其工作模式为通过分布在全球的数百个边缘节点将用户请求接收并通过自建骨干网将这些请求投递到后端服务。GCLB 在没有配置 WAF 的时候,会无条件接收所有外部的 HTTP/HTTPS 请求,而不做任何限流。但是,在某些场景下,比如流量增长高于后端承载能力,或者遭到 CC 攻击的时候,用户希望负载均衡能
当GCP虚拟机实例需要额外的存储空间或增加的性能限制时,我们可以增加永久性磁盘的大小。无论磁盘是否挂接到正在运行的虚拟机,都可以增加磁盘大小。
注意:您只能增加磁盘大小,而不能减小磁盘大小。如需减小磁盘大小,您必须创建较小的新磁盘。在删除较大的原始磁盘之前,您需要为这两个磁盘付费。
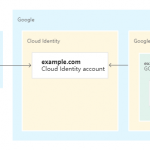
将 Microsoft Azure Active Directory (Azure AD) 设置为自动将用户预配到 Google Cloud Identity 或 Google Workspace。
实现使用 Azure AD 单点登录Google Cloud Platform等Google服务。
需要配置不同的防火墙规则(例如限制来源IP或放通不同的端口等)。如果遇到实例数量较多的时候这是一个较为头疼的问题,不少用户希望有一种方法能够高效的解决这个问题,减轻在使用GCP过程中的工作量。GCP网络标记则可以完美的解决这个需求。
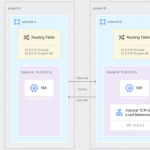
Google Cloud VPC 网络对等互连允许跨两个 Virtual Private Cloud (VPC) 网络的内部 IP 地址连接,无论它们是否属于同一个项目或同一个组织。VPC 网络对等互连可与 Compute Engine、GKE 和 App Engine 柔性环境配合使用。对等连接有以下优点:
网络延迟:使用内部地址的连接比使用外部地址的连接具有更低的延迟。
网络安全:服务所有者不需要将他们的服务暴露在公共互联网上,也不需要处理相关的风险。
网络成本:Google Cloud会对使用外部IP地址通信的网络收取出口带宽费用,即使流量在同一区域内。但是,如果网络是对等的,它们可以使用内部IP地址通信,从而节省出口费用。普通的网络定价仍然适用于所有流量。
Dataproc 是一项完全托管且高度可扩展的服务,用于在 Google Cloud Platform 上运行 Apache Hadoop、Apache Spark、Apache Flink、Presto 等 30 多个开源工具和框架。 Dataproc 既能利用开源数据处理的强大功能和灵活性,又省去了管理自己的基础设施的麻烦和成本。