作者:MeshCloud脉时云CSM邓军
一、概述
Cloud Data Fusion 是一项全托管式云原生企业数据集成服务,用于快速构建和管理数据流水线。Cloud Data Fusion 网页界面可让您构建可伸缩的数据集成解决方案,以便清理、准备、混合、转移和转换数据,而无需管理基础架构。(Cloud Data Fusion 由开源项目 CDAP 提供支持。)
除了批处理管道之外,Data Fusion 还允许您创建可以在事件生成时对其进行处理的实时管道。 目前,实时流水线在 Cloud Dataproc 集群上使用 Apache Spark Streaming 执行。 本实验将教您如何使用 Data Fusion 构建流式处理管道。
您将创建一个从 Cloud Pub/Sub 主题读取数据并处理事件、运行一些转换并将输出写入 BigQuery 的管道。
二、实验内容
- 了解如何创建实时管道
- 了解如何在 Data Fusion 中配置 Pub/Sub 源插件
- 了解如何使用 Wrangler 为位于不受支持的连接中的数据定义转换
三、实验步骤
Step 1. 检查项目权限
在开始使用 Google Cloud 之前,您必须确保您的项目在身份和访问管理 (IAM) 中具有正确的权限。
在 Google Cloud 控制台中,在导航菜单( 导航菜单图标) 上,单击IAM & Admin > IAM。
确认默认计算服务帐户{project-number}-compute@developer.gserviceaccount.com存在并且已editor分配角色。帐户前缀是项目编号,您可以在导航菜单>云概览中找到它。
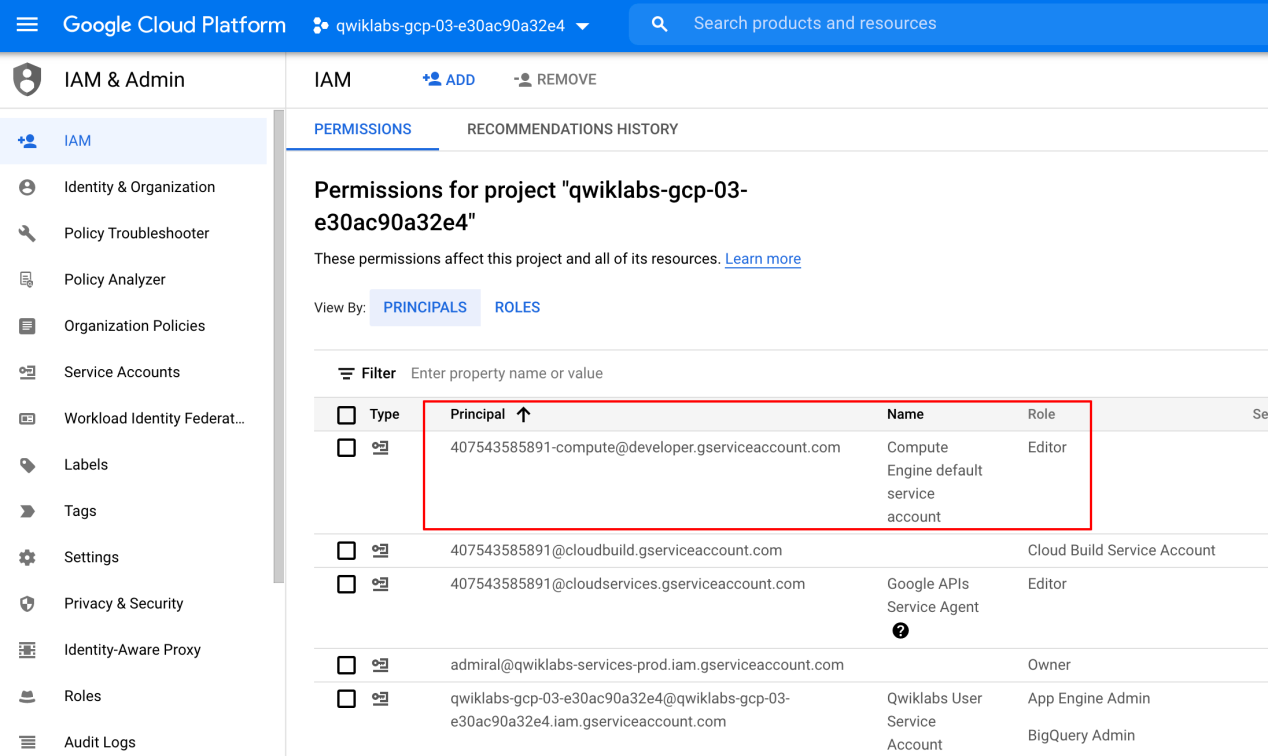
如果账户不在 IAM 中或没有角色editor,请按照以下步骤分配所需的角色。
- 在 Google Cloud 控制台中,在导航菜单上,点击云概览。
- 从项目信息卡中,复制项目编号。
- 在导航菜单上,单击IAM 和管理> IAM。
- 在IAM页面的顶部,单击添加。
- 对于New principals(替换{project-number}为您的项目编号),键入:
{project-number}-compute@developer.gserviceaccount.com
- 对于选择角色,选择基本(或项目)>编辑器。
- 单击保存。
Step 2. 确保数据流 API 已成功启用
为确保访问必要的 API,请重新启动与 Dataflow API 的连接。
1.在 Cloud Console 的顶部搜索栏中输入“Dataflow API”。单击Dataflow API的结果。
2.单击管理。
3.单击禁用 API。
4.如果要求确认,请单击“禁用”。
5.单击启用。
Step 3. 加载数据
- 首先,您需要将示例推文下载到您的计算机中。您稍后将使用 Wrangler 上传此文件以创建转换步骤。
您还需要在 Cloud Storage 存储桶中暂存相同的示例推文文件。在本实验即将结束时,您会将存储桶中的数据流式传输到发布/订阅主题中。
- 在 Cloud Shell 中,执行以下命令以创建新存储桶:
export BUCKET= $GOOGLE_CLOUD_PROJECT
gsutil mb gs:// $BUCKET
- 运行以下命令将推文文件复制到存储桶中:
gsutil cp gs://cloud-training/OCBL164/pubnub_tweets_2019-06-09-05-50_part-r-00000 gs:// $BUCKET
- 验证文件是否已复制到您的 Cloud Storage 存储桶中。
Step 4. 设置 Pub/Sub 主题
要使用 Pub/Sub,您可以创建一个主题来保存数据,并创建一个订阅来访问发布到该主题的数据。
- 在 Cloud Console 中,从导航菜单中点击发布/订阅,然后选择主题。
- 单击创建主题。
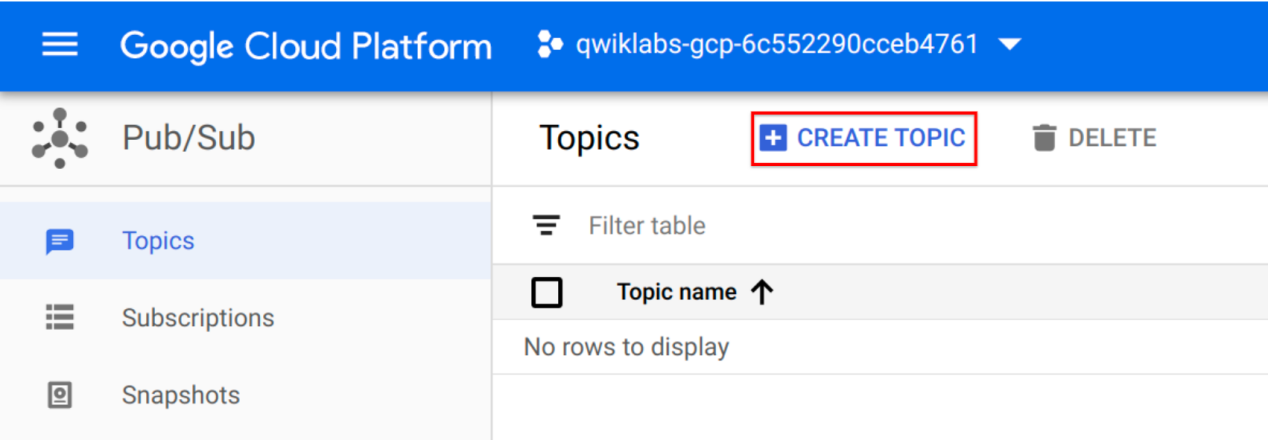
- 主题必须有一个唯一的名称。对于本实验,为您的主题命名cdf_lab_topic,然后单击创建。
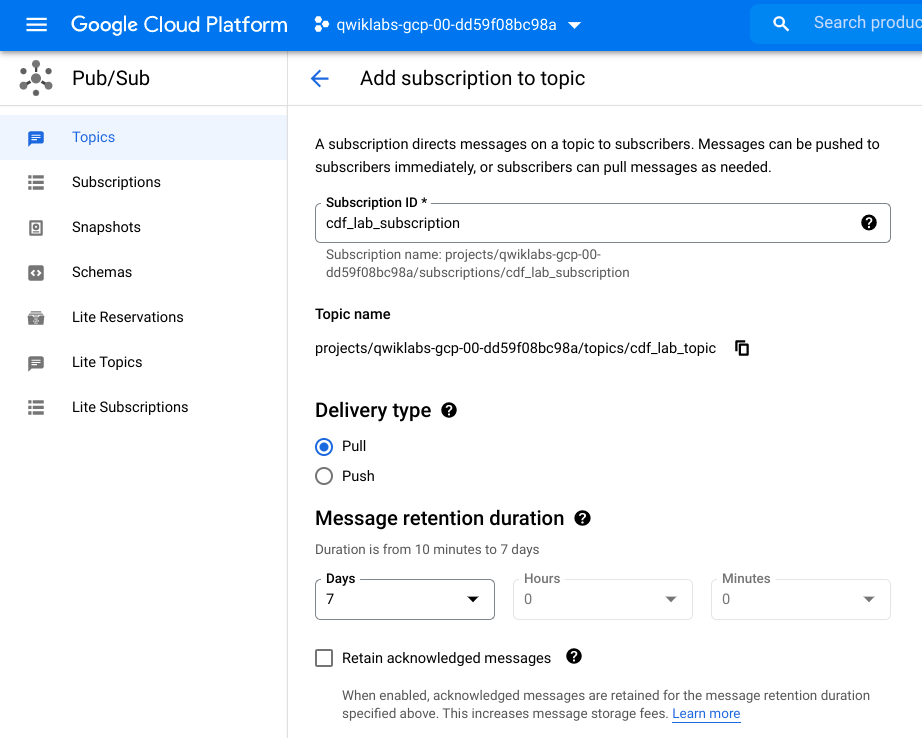
Step 5. 添加 Pub/Sub 订阅
仍在主题页面上。现在您将订阅以访问该主题。
- 单击创建订阅。
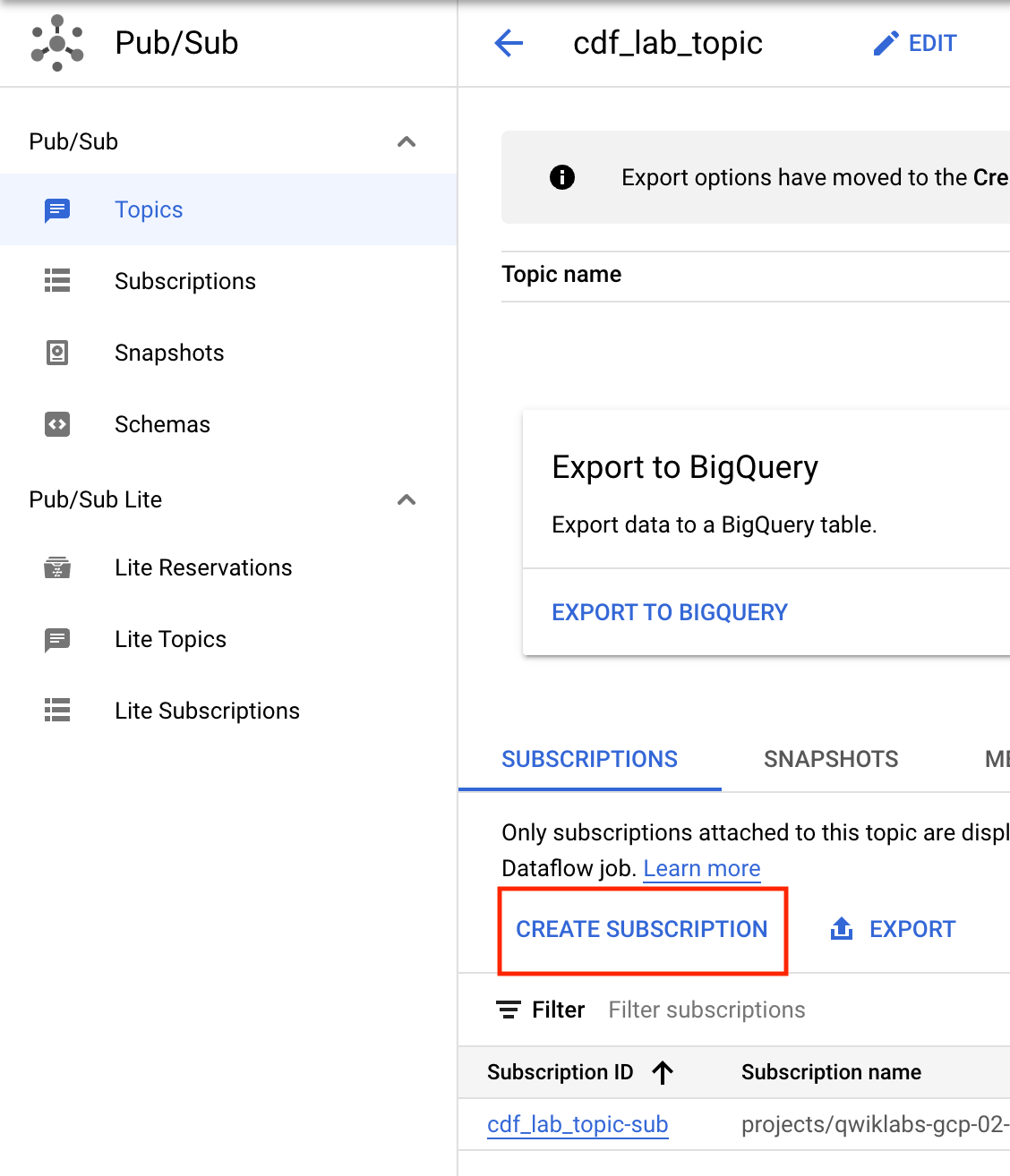
- 为订阅键入一个名称,例如cdf_lab_subscription,将 Delivery Type 设置为Pull,然后单击Create。
Step 6. 为您的 Cloud Data Fusion 实例添加必要的权限
接下来,您将使用以下步骤向与实例关联的服务帐户授予权限。
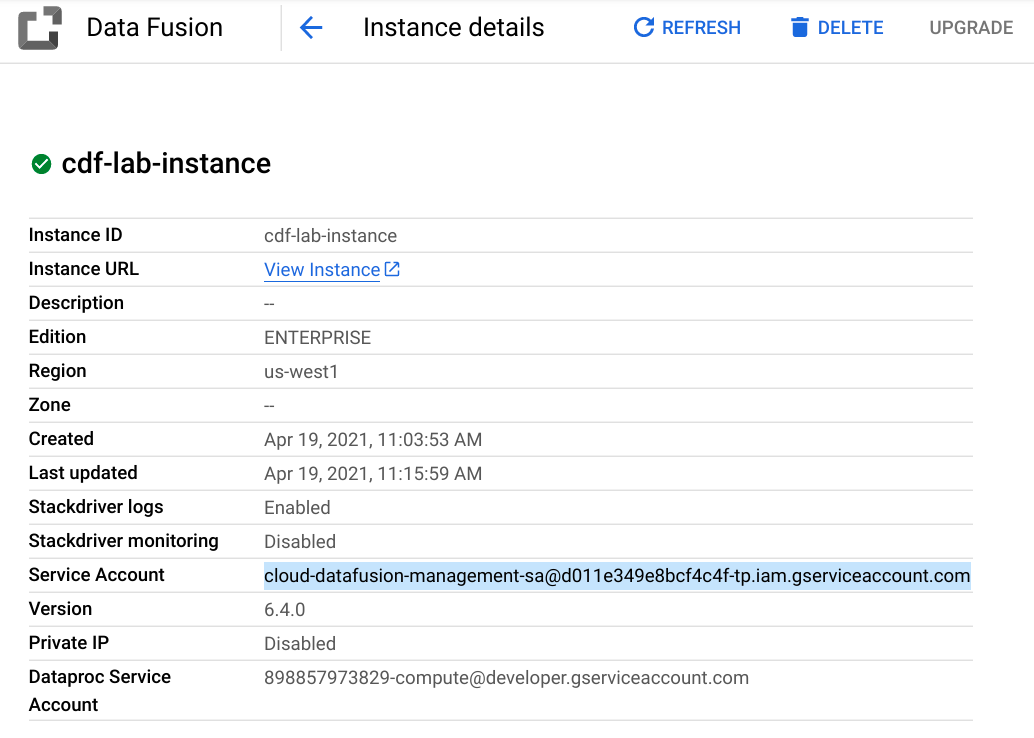
- 在 Cloud Console 中,从导航菜单中选择数据融合>实例。您应该会看到一个 Cloud Data Fusion 实例已经设置好并可以使用了。
接下来,您将使用以下步骤向与实例关联的服务帐户授予权限。
- 单击实例名称。在实例详细信息页面上,将服务帐户复制到剪贴板。
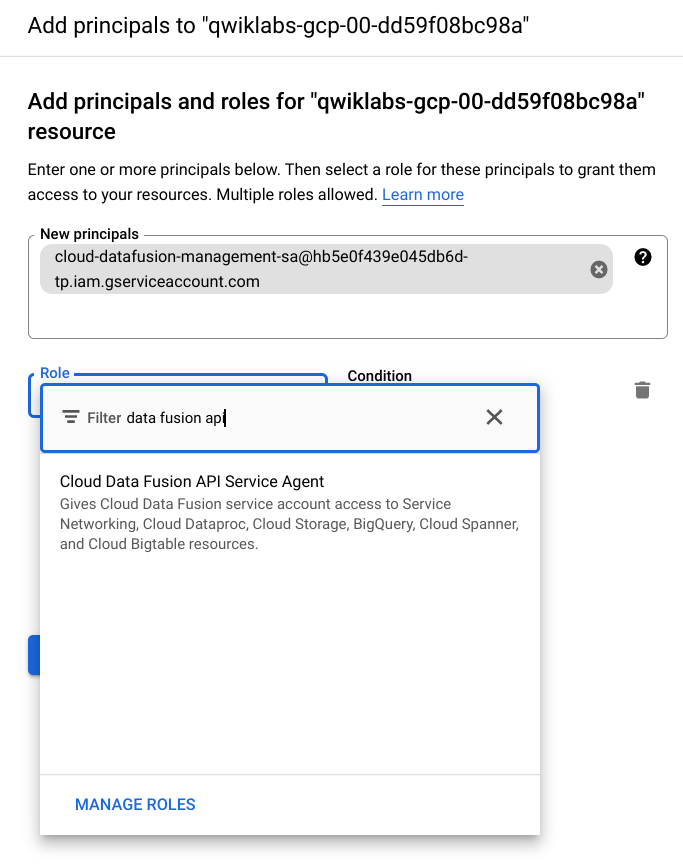
- 在 Cloud Console 中导航到IAM & Admin > IAM。
- 在 IAM 权限页面上,单击+Grant Access。
- 在New Principals字段中粘贴服务帐户。
- 单击Role字段并开始输入Cloud Data Fusion API Service Agent,然后选择它。
- 单击保存
Step 7. 授予服务帐户用户权限
- 在控制台的Navigation menu上,单击IAM & admin > IAM。
- 选中包括 Google 提供的角色授权复选框。
- 向下滚动列表以找到 Google 管理的 Cloud Data Fusion 服务帐户service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com,然后将服务帐户名称复制到剪贴板。

- 接下来,导航到IAM & admin > Service Accounts。
- 单击看起来像 的默认计算引擎帐户{project-number}-compute@developer.gserviceaccount.com,然后选择顶部导航中的权限选项卡。
- 单击“授予访问权限”按钮。
- 在New Principals字段中,粘贴您之前复制的服务帐户。
- 在Role下拉菜单中,选择Service Account User。
- 单击保存。
Step 8. 浏览 Cloud Data Fusion UI
使用 Cloud Data Fusion 时,您可以同时使用 Cloud Console 和单独的 Cloud Data Fusion 界面。在 Cloud Console 中,您可以创建 Cloud Console 项目,以及创建和删除 Cloud Data Fusion 实例。在 Cloud Data Fusion UI 中,您可以使用各种页面(例如Pipeline Studio或Wrangler)来使用 Cloud Data Fusion 功能。
要导航 Cloud Data Fusion 用户界面,请执行以下步骤:
- 在 Cloud Console 中返回Data Fusion,然后点击Data Fusion 实例旁边的View Instance链接。选择您的实验室凭据以登录。如果系统提示您浏览该服务,请单击不,谢谢。您现在应该位于 Cloud Data Fusion UI 中。
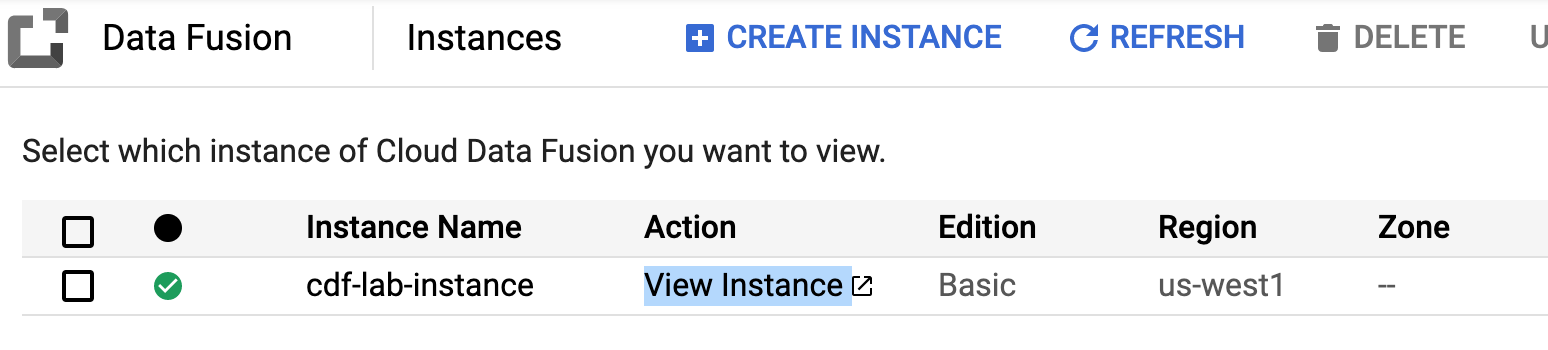
- 在 Cloud Data Fusion Control Center 上,使用Navigation 菜单显示左侧菜单,然后选择Pipeline > Studio。
- 在左上角,使用下拉菜单选择Data Pipeline – Realtime。
Step 9. 构建实时Pipeline
在处理数据时,能够方便地查看原始数据的外观,以便您可以将其用作转换的起点。为此,您将使用 Wrangler 来准备和清理数据。这种数据优先的方法将使您能够快速可视化您的转换,而实时反馈可确保您走在正确的轨道上。
- 从插件面板的Transform部分,选择Wrangler。Wrangler 节点将出现在画布上。单击“属性”按钮打开它。
- 单击指令部分下的WRANGLE按钮。
- 加载后,在左侧菜单中单击“上传”。接下来,单击上传图标将您之前下载的示例推文文件上传到您的计算机中。
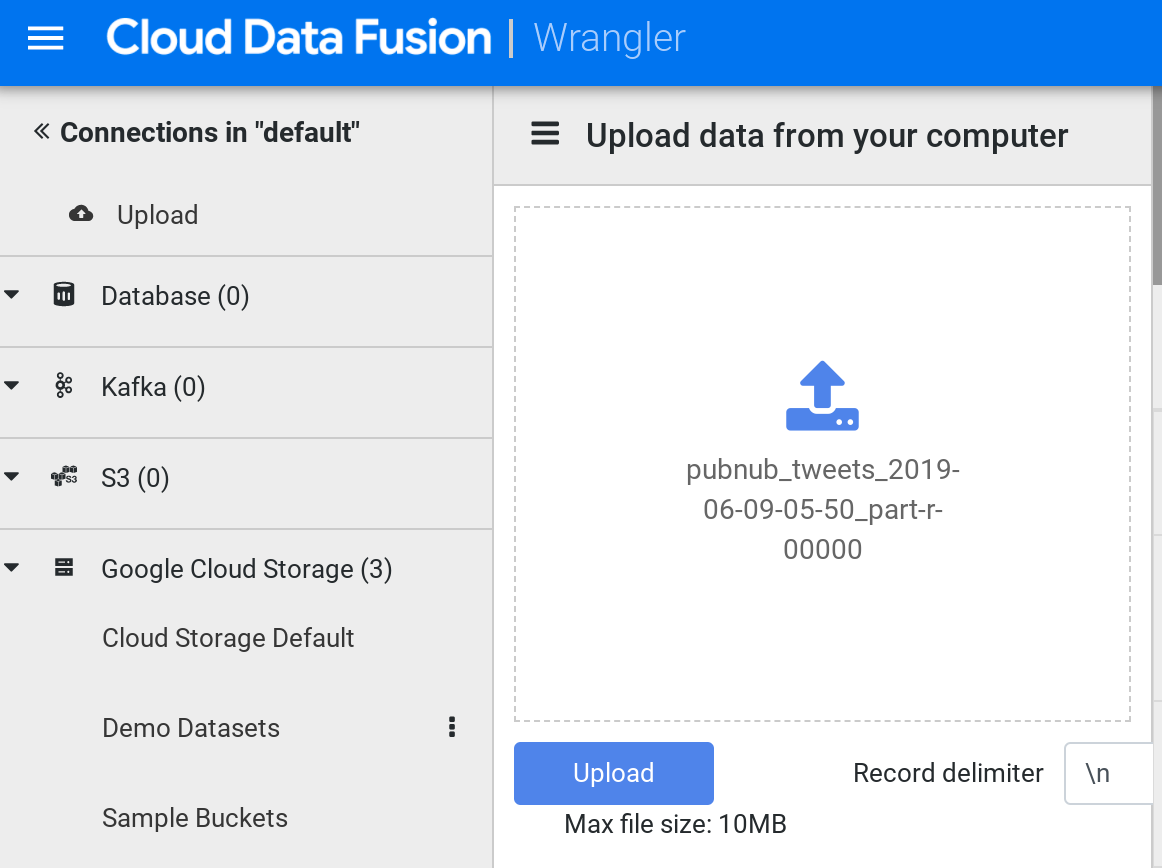
- 数据以行/列形式加载到 Wrangler 屏幕中。这将需要几分钟。
注意:将此视为您最终将在 Pub/Sub 中收到的事件示例。这是真实场景的代表,在这些场景中,您通常无法在开发管道时访问生产数据。
但是,您的管理员可能会允许您访问一个小样本,或者您可能正在处理遵守 API 合同的模拟数据。在本节中,您将迭代地对此示例应用转换,并在每个步骤中提供反馈。然后您将学习如何在真实数据上重放转换。
- 第一个操作是将 JSON 数据解析为分成行和列的表格表示形式。为此,您将从第一列(正文)标题中选择下拉图标,然后选择Parse菜单项,然后 从子菜单中选择JSON 。在弹出窗口中,将Depth设置为1,然后单击Apply。
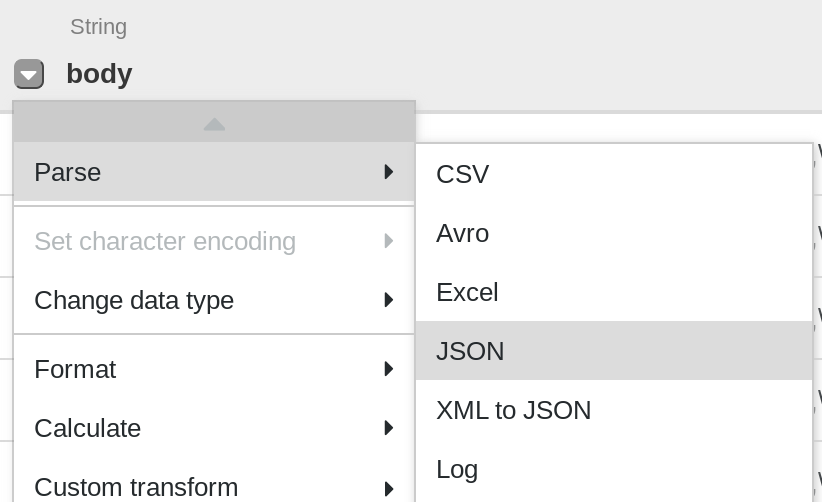
- 重复上一步,可以看到更有意义的数据结构,进行进一步的改造。单击body列下拉图标,然后选择Parse > JSON并将Depth设置为1,然后单击Apply。
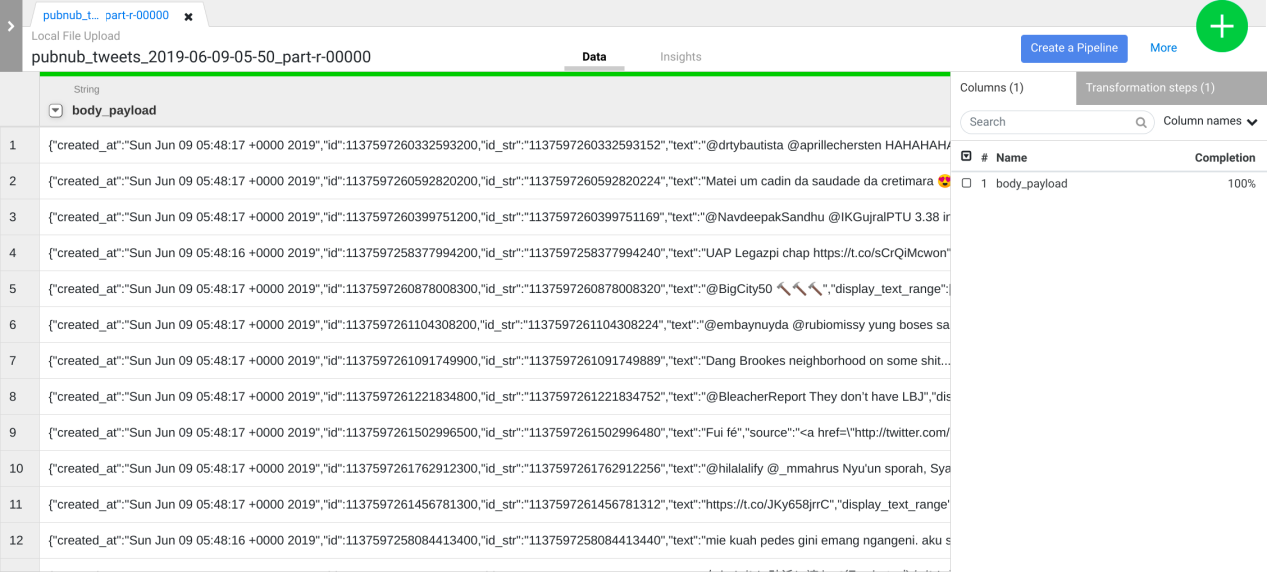
除了使用 UI,您还可以将 Transformation Steps 写入 Wrangler 指令命令行框中。此框出现在 wrangler UI 的下部(查找带有绿色$提示符的命令控制台)。您将在下一步中使用命令控制台粘贴一组转换步骤。
- 通过复制所有并粘贴到 Wrangler 指令命令行框中来添加下面的转换步骤:
columns-replace s/^body_payload_//g
drop id_str
parse-as-simple-date :created_at EEE MMM dd HH:mm:ss Z yyyy
drop display_text_range
drop truncated
drop in_reply_to_status_id_str
drop in_reply_to_user_id_str
parse-as-json :user 1
drop coordinates
set-type :place string
drop geo,place,contributors,is_quote_status,favorited,retweeted,filter_level,user_id_str,user_url,user_description,user_translator_type,user_protected,user_verified,user_followers_count,user_friends_count,user_statuses_count,user_favourites_count,user_listed_count,user_is_translator,user_contributors_enabled,user_lang,user_geo_enabled,user_time_zone,user_utc_offset,user_created_at,user_profile_background_color,user_profile_background_image_url,user_profile_background_image_url_https,user_profile_background_tile,user_profile_link_color,user_profile_sidebar_border_color,user_profile_sidebar_fill_color,user_profile_text_color,user_profile_use_background_image
drop user_following,user_default_profile_image,user_follow_request_sent,user_notifications,extended_tweet,quoted_status_id,quoted_status_id_str,quoted_status,quoted_status_permalink
drop user_profile_image_url,user_profile_image_url_https,user_profile_banner_url,user_default_profile,extended_entities
fill-null-or-empty :possibly_sensitive ‘false’
set-type :possibly_sensitive boolean
drop :entities
drop :user_location
注意:如果消息显示为“无数据”。尝试删除一些转换步骤。然后通过单击X删除任何一个转换步骤,一旦数据出现,您就可以继续进行。
- 单击右上角的“应用”按钮。接下来,单击右上角的X关闭属性框。
如您所见,您回到了Pipeline Studio中,画布上放置了一个节点,代表您刚刚在Wrangler中定义的转换。但是,没有源连接到此管道,因为如上所述,您将这些转换应用于笔记本电脑上的代表性数据样本,而不是实际生产位置的数据。
在下一步中,让我们指定数据的实际位置。
- 从插件面板的Source部分,选择PubSub。PubSub 源节点将出现在画布上。单击“属性”按钮打开它。
- 指定 PubSub 源的各种属性,如下所示:
A。在Reference Name下,输入Twitter_Input_Stream
b. 在订阅下输入cdf_lab_subscription(这是您之前创建的 PubSub 订阅的名称)
注意: PubSub 源不接受完全限定的订阅名称,但只接受 …/subscriptions/ 部分之后的最后一个组件。
C。单击验证以确保不会发现任何错误。
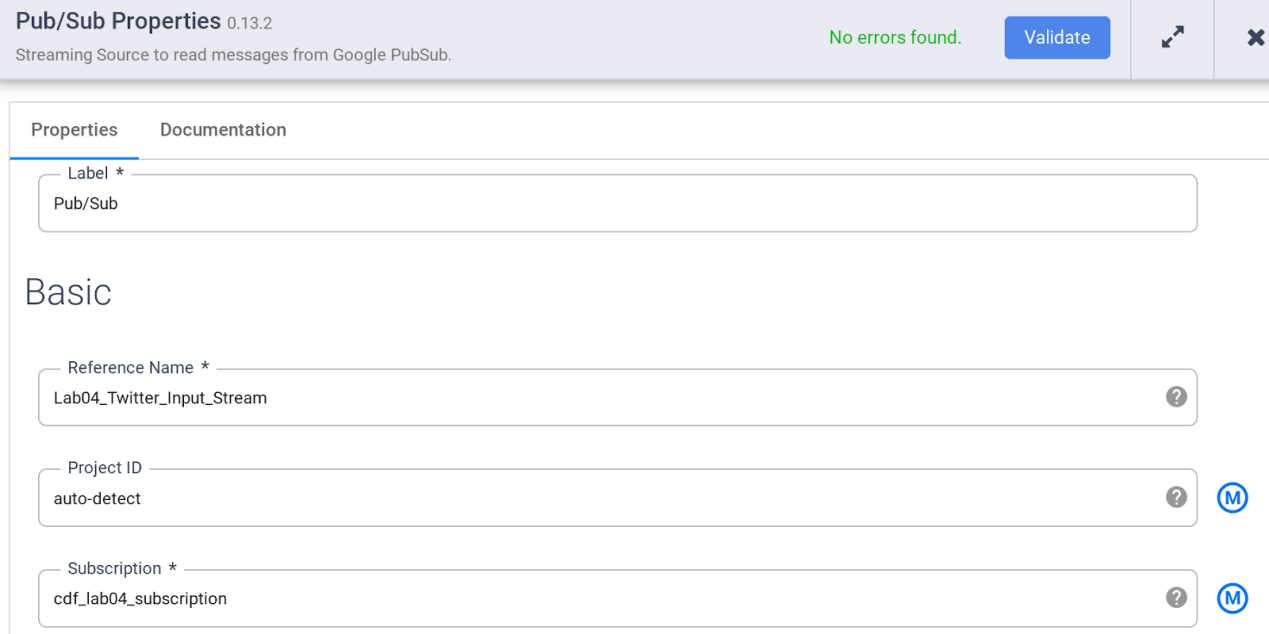
d. 单击右上角的X关闭属性框。
11. 现在将 PubSub 源节点连接到您之前添加的 Wrangler 节点。
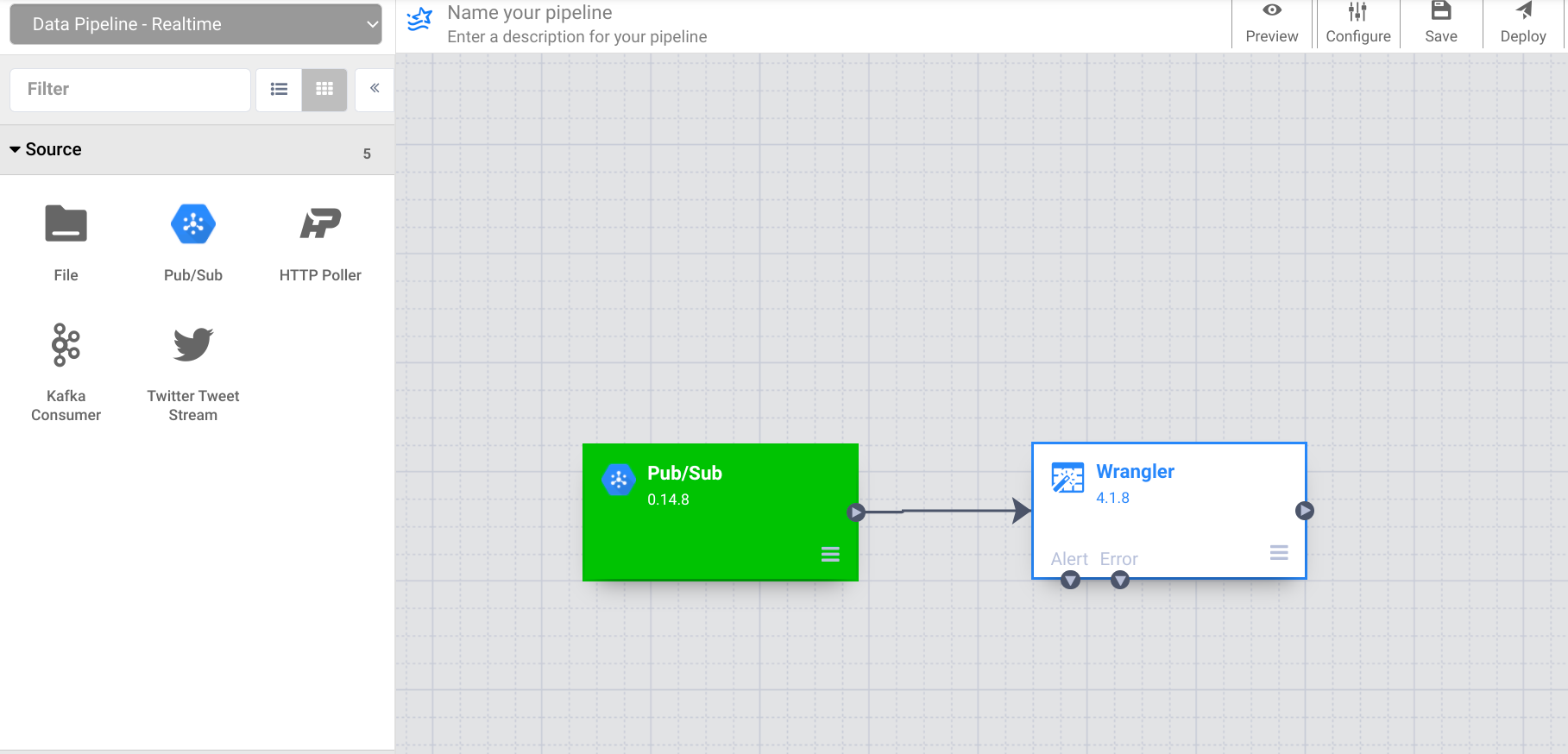
请注意,由于您之前在 Wrangler 中使用了数据示例,因此源列在 Wrangler 中显示为正文。但是,PubSub 源在名称为 message 的字段中发出它。在下一步中,您将解决此差异。
- 打开Wrangler 节点的属性并在现有转换步骤的顶部添加以下指令:
保持:消息
设置字符集:消息’utf-8′
重命名:消息:正文
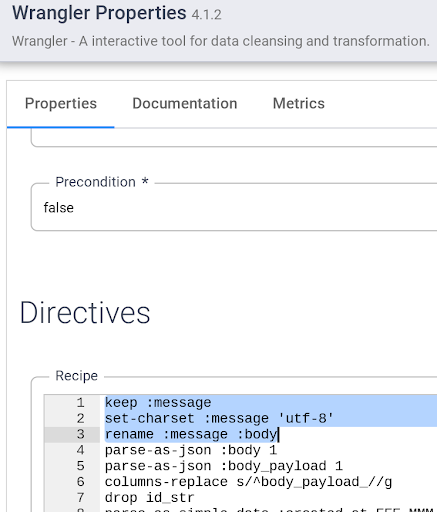
单击右上角的X关闭属性框。
- 现在您已将源和转换连接到管道,通过添加接收器来完成它。从左侧面板的Sink部分,选择BigQuery。画布上会出现一个 BigQuery 接收器节点。
- 通过将箭头从 Wrangler 节点拖动到 BigQuery 节点,将 Wrangler 节点连接到 BigQuery 节点。接下来,您将配置 BigQuery 节点属性。

- 将鼠标悬停在BigQuery节点上并单击Properties。
A。在Reference Name下,输入realtime_pipeline
b. 在数据集下,输入realtime
C。在Table下,输入tweets
d. 单击验证以确保不会发现任何错误。
- 单击右上角的X关闭属性框。
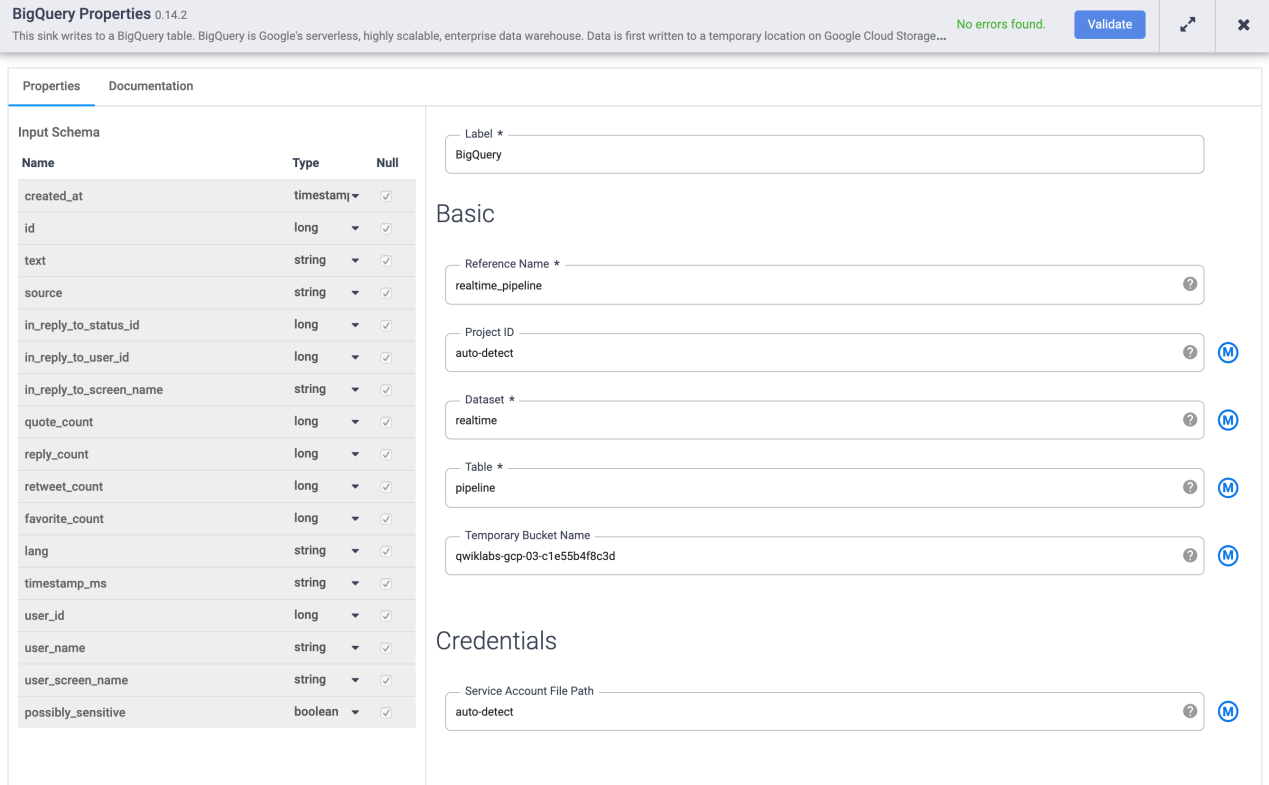
- 单击Name your pipeline,添加Realtime_Pipeline为名称,然后单击Save。
- 单击部署图标,然后启动管道。
- 部署后,单击运行。等待管道Status更改为Running。这将需要几分钟。
Step 10. 将消息发送到 Cloud Pub/Sub
通过使用数据流模板将事件批量加载到订阅中来发送事件。
您现在将创建一个基于模板的数据流作业,以处理来自推文文件的多条消息并将它们发布到之前创建的 pubsub 主题上。在数据流创建作业页面的连续处理数据(流)Text Files on Cloud Storage to Pub/Sub模板下使用。
- 返回 Cloud Console,转到Navigation menu > Dataflow。
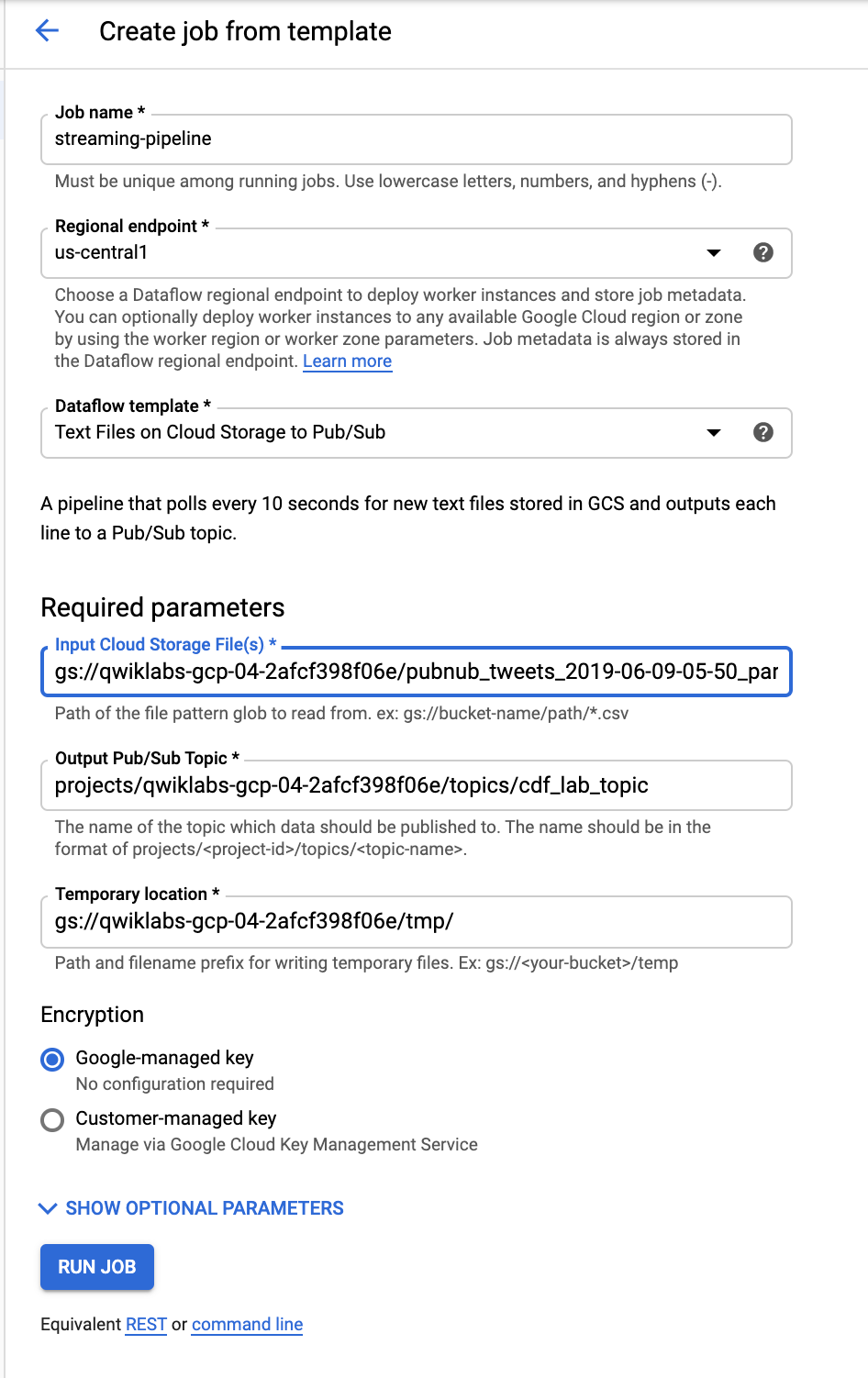
- 在顶部菜单栏中,单击CREATE JOB FROM TEMPLATE。
- 输入streaming-pipeline作为 Cloud Dataflow 作业的作业名称。
- 在 Cloud Dataflow 模板下,选择Text Files on Cloud Storage to Pub/Sub模板。
- 在Input Cloud Storage File(s)下,输入 gs://<YOUR-BUCKET-NAME>/<FILE-NAME> Be sure to replace <YOUR-BUCKET-NAME>with your bucket name and <FILE-NAME>with the name of the file which you earlier downloaded to your computer.
例如:gs://qwiklabs-gcp-01-dfdf34926367/pubnub_tweets_2019-06-09-05-50_part-r-00000
- 在Output Pub/Sub Topic下,输入projects/<PROJECT-ID>/topics/cdf_lab_topic
请务必将PROJECT-ID替换为您的实际项目 ID。
- 在临时位置下,输入gs://<YOUR-BUCKET-NAME>/tmp/
- 单击运行作业按钮。
- 执行数据流作业并等待几分钟。您可以在 pubsub 订阅上查看消息,然后查看正在通过实时 CDF 管道处理的消息。
Step 10. 查看您的管道指标
一旦事件加载到 Pub/Sub 主题中,您应该开始看到它们被管道消耗 – 观察每个节点上的指标是否更新。
- 在 Data Fusion 控制台中,等待您的管道指标发生变化

参考链接:
【1】创建Data Fusion数据流水线
https://cloud.google.com/data-fusion/docs/create-data-pipeline?hl=zh-cn
【2】从 Pub/Sub 流式传输来源读取
https://cloud.google.com/data-fusion/docs/how-to/connect-to-pubsub-streaming-source?hl=zh-cn
【3】Pub/Sub 创建拉取订阅
https://cloud.google.com/pubsub/docs/create-subscription?hl=zh-cn